仅对英特尔可见 — GUID: rxr1533827311846
Ixiasoft
1.9.6. 分形综合优化
分形综合优化利于深度学习加速器和其他超出所有可用DSP资源的高吞吐量,计算密集型设计。对于这类型设计,分形综合优化可实现面积缩减20-45%。
分形综合为一组综合优化,为计算密集型设计以最佳方式使用FPGA资源。这些综合优化由乘法器正则化(regularization)和重定时,以及连续计算包组成。此优化针对具有大量低精度计算操作(例如,加法和乘法)的设计。可使能全局分型综合或仅使能指定乘法器,具体请见使能或禁用用Fractal Synthesis中说明。
全工程分形综合考量
注: 分形综合优化最适合于使用深度学习加速器或其他超过所有DSP资源的高吞吐量,计算密集型功能。使能全项目分形综合会引起模块上出现不必要膨胀,从而不利于分形优化。使能全工程性分形综合优化之前,请先考虑如下因素:
- Intel FPGA器件包含数千个硬DSP块,极其适合运算操作。如果您设计中的运算函数总量较小,则无需使能Fractal Synthesis。该情况下,默认所有运算函数直接映射到DSP。仅当无足够DSP块实现全部运算单元时才使能全局Fractal Synthesis。且仅针对不需要Compiler映射到DSP的模块,才为其使能Fractal Synthesis。
- 在当前版本的 Intel® Quartus® Prime Pro Edition软件中,分形综合优化主要针对低精度乘法。请使用DSP块实现高精度乘法器(其中每操作数超过11位)。
- 如果使能全工程Fractal Synthesis,则以下信息消息编号20193可能在编译过程中产生:
Applied dense packing to "<entity>". Area: 2 LABs. Logic density: 0.775.
该信息显示Compiler效力是将计算性逻辑封装到更少量的LAB中。如果设计已被高度使用,则Compiler会跳过该阶段。
- 确认消息报告Area未超出100个LAB。如果Area超出100个LAB,则将分形综合块划分成子块,并将分形综合优化分别分配到各子块。
- 验证消息报告的逻辑密度是否大于0.75。如果逻辑密度小于0.75,则对该实体禁用Fractal Synthesis,因为通常通过标准综合会获得更好的密度。
| Area (LABs) | |||
|---|---|---|---|
| 器件 | Dot-product(向量点积) | Fractal Synthesis ON | Fractal Synthesis OFF |
| Intel® Arria® 10和 Intel® Cyclone® 10 GX | Sum of 16(4x4sm)(sign magnitude,有符号数据) | 12 | 19 |
| Sum of 16(5x5sm) | 19 | 32 | |
| Sum of 16(6x6sm) | 25 | 36 | |
| Sum of 16(7x7sm) | 34 | 44 | |
| Sum of 16(8x8sm) | 45 | 60 | |
| Intel® Stratix® 10和 Intel® Agilex™ 器件 | Sum of 16(4x4sm) | 15 | 22 |
| Sum of 16(5x5sm) | 21 | 39 | |
| Sum of 16(6x6sm) | 29 | 47 | |
| Sum of 16(7x7sm) | 39 | 55 | |
| Sum of 16(8x8sm) | 55 | 71 | |
乘法器正则化与重定时
乘法器正则化和重定时执行高度优化软乘法器实现的推断。如果需要,Compiler会对两个或多个流水线阶段应用反向重定时。使能分形综合后,Compiler对signed(有符号)和unsigned (无符号)乘法器应用乘法器正则化和重定时。
图 49. 乘法器重定时
注:
- 乘法器正则化仅使用逻辑资源,不使用DSP块。
- 在设置了FRACTAL_SYNTHESIS QSF分配的模块中,乘法器正则化和重定时适用于signed和unsigned乘法器。
乘法器正则化实例
如下为简单无符号点积设计实例,包含5位操作数乘法运算符。这些短乘法器是乘法器正则化的理想选择。
(* altera_attribute = "-name FRACTAL_SYNTHESIS ON" *)
module dot_product(
input clk,
input [4:0] a, b, c, d, e, f, g, h,
output reg [11:0] out
);
reg [9:0] ab, cd, ef, gh;
reg [10:0] ab_cd, ef_gh;
always @(posedge clk)
begin
ab <= a * b;
cd <= c * d;
ef <= e * f;
gh <= g * h;
ab_cd <= ab + cd;
ef_gh <= ef + gh;
out <= ab_cd + ef_gh;
end
endmodule
module top(
input clk,
input [4:0] a1, b1, c1, d1, e1, f1, g1, h1,
input [4:0] a2, b2, c2, d2, e2, f2, g2, h2,
output [11:0] out1, out2
);
dot_product core1(.clk(clk), .a(a1), .b(b1), .c(c1), .d(d1),
.e(e1), .f(f1), .g(g1), .h(h1), .out(out1));
dot_product core2(.clk(clk), .a(a2), .b(b2), .c(c2), .d(d2),
.e(e2), .f(f2), .g(g2), .h(h2), .out(out2));
endmodule
Intel® Quartus® Prime综合将如下信息输出到控制台:
图 50. Console Messages(控制台消息)

在Chip Planner中,可观察到该设计具有2个无符号向量点击核。这些核经过单独优化和放置。LAB资源优化度近乎100%,如下图所示:
图 51. 设计布局

有符号向量点积常用于深度学习(deep-learning)应用程序。有符号的向量点积实例演示如下:
(* altera_attribute = "-name FRACTAL_SYNTHESIS ON" *)
module dot_product(
input signed clk,
input signed [4:0] a, b, c, d, e, f, g, h,
output reg signed [11:0] out
);
reg signed [9:0] ab, cd, ef, gh;
reg signed [10:0] ab_cd, ef_gh;
always @(posedge clk)
begin
ab <= a * b;
cd <= c * d;
ef <= e * f;
gh <= g * h;
ab_cd <= ab + cd;
ef_gh <= ef + gh;
out <= ab_cd + ef_gh;
end
endmodule
module top(
input clk,
input signed [4:0] a1, b1, c1, d1, e1, f1, g1, h1,
input signed [4:0] a2, b2, c2, d2, e2, f2, g2, h2,
output signed [11:0] out1, out2
);
dot_product core1(.clk(clk), .a(a1), .b(b1), .c(c1), .d(d1),
.e(e1), .f(f1), .g(g1), .h(h1), .out(out1));
dot_product core2(.clk(clk), .a(a2), .b(b2), .c(c2), .d(d2),
.e(e2), .f(f2), .g(g2), .h(h2), .out(out2));
endmodule
Intel® Quartus® Prime综合显示在控制台中显示以下消息:
图 52. 控制台消息
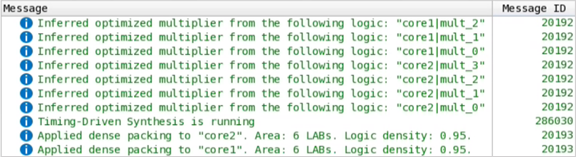
在Chip Planner中,可观察到该设计具有2个有符号的向量点积核经过单独优化和放置:
图 53. 设计布局

连续计算包
连续计算包将计算门控重新综合成最佳尺寸的逻辑块以适合 Intel® FPGA LAB。此优化允许计算块的LAB资源利用率最高达到100%。
使能分形综合后,Compiler将此优化应用于所有进位链和双输入逻辑门控。该优化可打包加法器树(adder tree),乘法器和任何计算相关的逻辑。
图 54. 连续计算包
请注意连续计算包独立于乘法器正则化而运行。因此如果使用未经正则化的乘法器(如,编写自己的乘法器),则连续计算包仍可运行。