仅对英特尔可见 — GUID: vsx1598364879665
Ixiasoft
产品终止通知
1. Intel® FPGA SDK for OpenCL™ Pro Edition最佳实践指南介绍
2. 查看您Kernel的report.html文件
3. OpenCL内核设计概念
4. OpenCL内核设计最佳实践
5. 分析(Profiling)您的内核来识别性能瓶颈
6. 提高单个Work-Item内核性能的策略
7. 提高NDRange内核数据处理效率的策略
8. 提高存储器访问效率的策略
9. 优化FPGA面积使用的策略
10. 优化英特尔 Stratix 10 OpenCL设计的策略
11. 提高主机应用程序性能的策略
12. Intel® FPGA SDK for OpenCL™ Pro版最佳实践指南存档
A. Intel® FPGA SDK for OpenCL™ Pro版最佳实践指南修订历史
仅对英特尔可见 — GUID: vsx1598364879665
Ixiasoft
3.4.6. 循环瓶颈(Loop Bottleneck)
循环中的瓶颈意味着一个或者多个循环携带的依赖项导致编译器减少了并发处理的数据项的数量(同一周期中),或者fMAX被降低。瓶颈只在单个work-item内核上发生,并且总是针对循环创建。
在分析简单循环的吞吐量之前,了解动态启动间隔的概念很重要。启动间隔(II)是给定循环调用的连续迭代启动之间静态确定的周期数。然而,考虑到交叉存取,静态计划的II可能不同于实际实现的动态II。
注: 交叉存取允许多个循环调用的迭代并行执行,但前提是该循环的静态II大于1。默认情况下,循环的交叉存取的最大量等于该循环的静态II。
存在交叉存取的情况下,循环的动态II可以近似于循环的静态II除以交叉存取的程度,即,除以正在运行的循环的并发调用数。
简单循环实例
在简单循环中,最大数量的并发处理数据项(也称为最大并发数)可以表示为:
并发MAX = (块延迟 ×最大交叉存取迭代)/启动间隔
考虑以下简单循环:
1 kernel void lowered_fmax (global int *dst, int N) {
2 int res = N;
3 #pragma unroll 9
4 for (int i = 0; i < N; i++) {
5 res += 1;
6 res ^= i;
7 }
8 dst[0] = res;
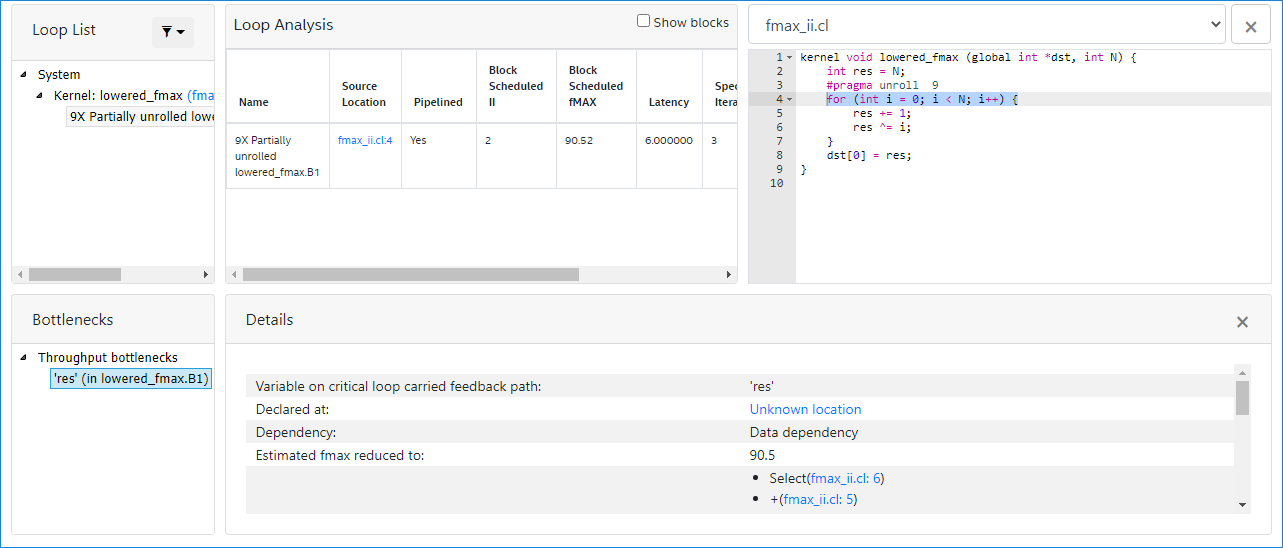
9 }Loop Analysis报告显示简单循环的内容如下:

line:4中的for循环的延迟为6,最大交叉存取迭代为1,以及启动间隔为2。因此,最大并发为3(延迟为6 / II为2)。该瓶颈是循环携带的依赖项的结果,而该依赖项是由于变量res上的数据依赖性引起的。Bottlenecks viewer中会报告该情况,如下图所示:
另外一种循环携带的依赖项是存储依赖,如以下实例所示:
for (…)
for (…)
… = mem[x];
mem[y] = …;
嵌套循环实例
在nested loop(嵌套循环)中,更难计算最大并发。例如,nested loop中循环携带的依赖项不一定影响外循环的启动间隔。此外,嵌套循环通常需要了解内部循环的跳变计数。请参考以下实例:
1 __kernel void serial_exe_sample( __global unsigned* restrict input,
2 __global unsigned* restrict output,
3 int N ) {
4 unsigned offsets[1024];
5 unsigned size[1024];
6 unsigned results[4];
7 for (unsigned i = 0; i < N; i++) {
8 offsets[i] = input[i];
9 }
10
11 for (unsigned i = 1; i < (N-1); i++) {
12 unsigned num = offsets[i];
13 unsigned sum = 0;
14 // There's a memory dependency, so the inner loops are executed
15 // serially, i.e. the both loops finish before the next iteration
16 // of i in the outer loop can start.
17 for (unsigned j = 0; j < num; j++) {
18 size[j] = offsets[i+j] - offsets[i+j-1];
19 }
20 for (unsigned j = 0; j < 4; j++) {
21 results[j] = size[j];
22 }
23 }
24
25 // store it back
26 #pragma unroll 1
27 for (unsigned i = 0; i < 4; i++) {
28 output[i] = results[i];
29 }
30 }本实例中,由变量size引起的存储依赖项导致循环携带依赖项,从而造成瓶颈。size变量必须在可以启动下一个外循环(line:11)迭代之前完成line:20中循环内的加载。因此,外循环的最大并发是1。在Loop Analysis和Schedule Viewer报告的详细信息部分中报告该信息。
解决瓶颈
要解决瓶颈,主要 考虑重新构建您的设计代码 。
重构后,考虑在阵列上应用应用以下pragma或属性:
- #pragma II。请参阅Intel FPGA SDK for OpenCL 编程指南中的Specifying a loop initiation interval (II)(指定循环启动间隔II)
- #pragma ivdep safelen。请查看移除由于对存储器阵列的访问而引起的循环依赖
- #pragma max_concurrency。请参阅Intel FPGA SDK for OpenCL Programming Guide中的Loop Interleaving Control(循环交叉存取控制)
- attribute private_copies。请参阅Intel FPGA SDK for OpenCL Programming Guide中的指定private_copies存储器属性
参考前面的简单循环实例,其中并发为3,而启动间隔为2。应用#pragma II 1(如以下代码片段所示)的代价是预测的fMAX从90MHz降低到50MHz:
1 kernel void lowered_fmax (global int *dst, int N) {
2 int res = N;
3 #pragma unroll 9
4 #pragma ii 1
5 for (int i = 0; i < N; i++) {
6 res += 1;
7 res ^= i;
8 }
9 dst[0] = res;
10 }