仅对英特尔可见 — GUID: rfr1469543500580
Ixiasoft
产品终止通知
1. Intel® FPGA SDK for OpenCL™ Pro Edition最佳实践指南介绍
2. 查看您Kernel的report.html文件
3. OpenCL内核设计概念
4. OpenCL内核设计最佳实践
5. 分析(Profiling)您的内核来识别性能瓶颈
6. 提高单个Work-Item内核性能的策略
7. 提高NDRange内核数据处理效率的策略
8. 提高存储器访问效率的策略
9. 优化FPGA面积使用的策略
10. 优化英特尔 Stratix 10 OpenCL设计的策略
11. 提高主机应用程序性能的策略
12. Intel® FPGA SDK for OpenCL™ Pro版最佳实践指南存档
A. Intel® FPGA SDK for OpenCL™ Pro版最佳实践指南修订历史
仅对英特尔可见 — GUID: rfr1469543500580
Ixiasoft
3.4.3. 嵌套循环
由于循环迭代依顺序进行, Intel® FPGA SDK for OpenCL™ Offline Compiler不推断流水线执行。因此,相对于下一个内部循环,外部循环(outer loop)迭代可能是无序的,因为内部循环迭代的次数可能针对各种外部循环迭代而不同。
要解决无序的外循环迭代问题,请将内部循环的下界(lower bound)和上界(upper bound) 设计为外部循环迭代之间不发生改变。
单个Work-Item执行
为确保FPGA上高吞吐量单个基于work-item的kernel执行, Intel® FPGA SDK for OpenCL™ Offline Compiler必须在任何给定时间并行处理多个流水线阶段。该并行性(parallelism)是通过流水线化循环的迭代来实现。
请参考如下简单实例代码,它显示为单个work-item的累加:
1 kernel void accum_swg (global int* a,
global int* c,
int size,
int k_size) {
2 int sum[1024];
3 for (int k = 0; k < k_size; ++k) {
4 for (int i = 0; i < size; ++i) {
5 int j = k * size + i;
6 sum[k] += a[j];
7 }
8 }
9 for (int k = 0; k < k_size; ++k) {
10 c[k] = sum[k];
11 }
12 }
每次循环迭代器件,从全局存储器a来的数据值被累加到sum[k]。该实例中,第4行上内部循环的启动间隔值为1,以及延迟为11。而外部循环也有一个启动间隔值大于或等于1,以及延迟为8。
注: 新循环迭代的启动频率被称为启动间隔(II)。II指的是流水线在可以处理下一个循环迭代之前必须等待的硬件时钟周期数。最佳展开循环的II值为1,因为每个时钟周期处理一个循环迭代。
图 60. 单个work-item Kernel的系统视图

下图说明i的每次迭代如何进入块:
图 61. 内部循环accum_swg.B2执行
您在观察外部循环时会看到,II值为1也意味着线程的每次迭代可在每个时钟周期进入。在本实例中,认为k_size为20和size为4。这样对于首8个时钟周期来说是正确的,因为外部循环迭代0到7可以进入,而且无任何下游(downstream)中止它。一旦 线程0进入内部循环,它需要4次迭代才能完成。线程1到8无法进入内部循环,并且它们会被线程0停顿4个周期。线程1在线程0的迭代完成后才进入内部循环。因此, 线程9在时钟周期13进入外循环。线程9到20每四个时钟周期进入循环, 这个由size的值决定。通过该实例,您可以观察到外循环的动态启动间隔大于静态预测的启动间隔1,并且它是内循环的行程计数的函数。
图 62. 单个Work-Item执行

非线性执行
循环结构不支持线性执行。以下代码实例显示外部循环i包含两个发散(divergent)的内部循环。外部循环的每次迭代都可能执行一个内部循环或者另一个内部循环,这是一种非线性执行模式。
__kernel void structure (__global unsigned* restrict output1,
__global unsigned* restrict output2,
int N) {
for (unsigned i = 0; i < N; i++) {
if ((i & 3) == 0) {
for (unsigned j = 0; j < N; j++) {
output1[i+j] = i * j;
}
}
else
{
for (unsigned j = 0; j < N; j++) {
output2[i+j] = i * j;
}
}
}
}Serial Regions(串行区域)
当内部循环访问导致外部循环依赖时,嵌套循环中就可能出现串行区域。由于数据或者存储器依赖性,该内部循环就成为外部循环迭代中的串行区域。
稳定状态下,外部循环的II = 内部循环的II *内部循环的形成计数。对于II大于1的内部循环,以及无串行执行区域的外部循环,就可能从外部循环交错线程。
请参考如下代码实例:
kernel void serially_execute (global int * restrict A,
global int * restrict B,
global int * restrict result,
unsigned N) {
int sum = 0;
for (unsigned i = 0; i < N; i++) {
int res;
for (int j = 0; j < N; j++) {
sum += A[i*N+j];
}
sum += B[i];
}
*result = sum;
}
该实例中,外部循环中的依赖项导致了内部循环的串行执行。性能上的主要区别是:外部循环的稳态II = 内部循环的II *(内部循环行程计数- 1)+延迟。该实例中,内部循环的II为1,以及延迟为4;外部循环的II为1,以及延迟为7。如果N较大,例如400,与延迟相比,则串行执行对外部循环的影响很小。
图 63. 内核的系统视图
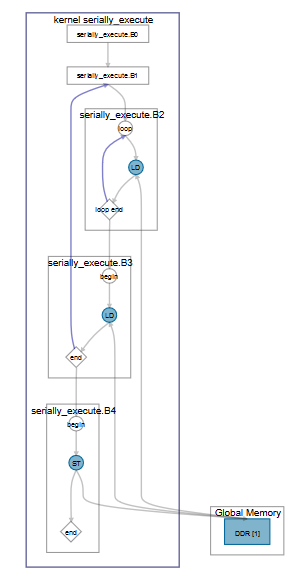
图 64. 串行执行
