The Challenge of AI Adoption
As important as artificial intelligence has become on a global scale to accelerate scientific discovery and transform consumer and business services, the reality remains that AI implementation is not occurring evenly. According to McKinsey’s The State of AI in 2022, adoption of AI by organizations has stalled at 50% and 53% of all AI projects fail to get into production.
This is concerning—the benefits of AI are too great to be in the hands of only a few, which makes this an opportune time to survey the challenges of going from AI concept to deployment.
For data scientists, AI starts as an end-to-end (E2E) pipeline including data engineering, experimentation, and live-streaming data using both classical machine learning (ML) and deep learning (DL) techniques. The E2E pipeline requires a balanced platform across memory, throughput, and dense matrix and general-purpose compute to optimally run any AI code.
For the line of business, AI is a capability that enhances an application and complies with service level agreements (SLAs) including throughput, latency, and platform flexibility. Projects have difficulty transitioning from experimentation to production because of waterfalling from the data team to model development to the team operationalizing from the data center to the factory floor. These stages are often done with different platforms, causing rework. A collaborative method pushes upstream the production SLA requirements and includes a single E2E platform architecture from data center to the edge.
Let’s discuss what that means.
What is a Universal AI Platform?
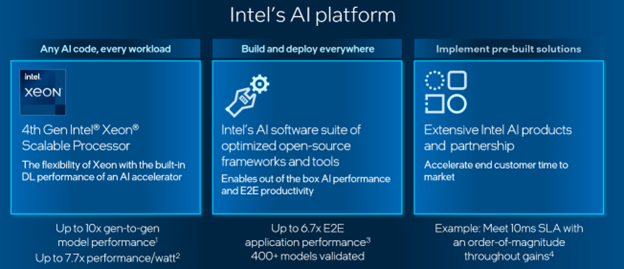
It’s a platform with flexibility to run every AI code, scope to empower every developer, and scale to enable AI everywhere.
Intel’s vision is to accelerate AI infusion into every application by delivering end-to-end application performance, as opposed to select DL or ML kernel performance. To scale AI, the full stack must be optimized from chips to software libraries to applications.
The 3 components of a universal AI platform are:
- General Purpose and AI-Specific Compute: 4th Gen Intel® Xeon® Scalable processors to run any AI code and every workload by combining the flexibility of a general-purpose CPU and the performance of a deep-learning accelerator. The processors can also integrate effortlessly with other processors and specialized accelerators, including GPUs and ASICs.
- Open, Standards-based Software: An AI software suite of open source frameworks and AI model and E2E optimization tools for developers to build and deploy AI everywhere.
- Ecosystem Engagement: Pre-built solutions with Intel partners to address the business needs of end customers and accelerate time to market.
Run Any AI Code and Every Workload
AI on CPUs has the advantages of ubiquity, flexibility, and programming model familiarity. This is especially true for 4th Gen Intel® Xeon® Scalable processors, which are balanced for optimal performance across workloads with the built-in performance of an AI accelerator.
The E2E pipeline includes general compute functions for ingestion and classical machine learning, which are more complex given their irregular and sparse nature than the small-matrix-dense-algebra of deep learning. The data and ML stages account for most AI-application compute cycles and already run well on Intel Xeon processors. Additionally, advances in compute, memory, and bandwidth along with Intel’s recent software optimizations deliver 1.9X6 higher classical ML performance compared to AMD.
To address deep learning, the Intel® Advanced Matrix Extensions (Intel® AMX) BF16 and INT8 matrix multiplication engine is integrated into every core. It builds upon vector extensions in previous generations of Xeon and delivers up to 10x1 higher gen-to-gen inferencing and training model performance with no code changes using any framework.
Takeaway: the 4th Gen Intel Xeon Scalable Processor with its ability to accelerate the E2E AI pipelines is the ideal foundation for a universal AI platform.
Open, Optimized Software to Build and Deploy AI Everywhere
Rolling out simultaneously with the 4th Gen Intel Xeon Scalable processors is Intel’s largest AI software suite to date—the company’s mantra is to enable developers to use any tools and focus on their model. This is done by automating tasks and accelerating productivity while supporting industry-standard, open-source libraries. The software suite components include:
- A full set of popular native operating system and hypervisor support.
- The oneAPI unified programming model of performant libraries for heterogeneous architectures, including Intel Xeon processors, Intel® Xe GPUs, and other accelerators.
- Any AI framework with orders-of-magnitude performance optimizations. TensorFlow*,PyTorch*,Scikit-learn*,XGBoost*, Modin* and others include optimizations up-streamed into the latest stock AI frameworks, and Intel extensions deliver the latest optimizations. Developers can build upon their existing code base and use their favorite framework with no/minimal code changes with 10-100X performance gains. Over 400+ DL and ML models were validated with these industry-standard libraries and frameworks.
- Tools that automate AI tasks. AI tools for data preparation, training, inference, deployment, and scaling boost developer productivity. They include the Intel® AI Analytics Toolkit for end-to-end data science workflows, BigDL for scaling AI models on legacy big-data clusters, Intel® Neural Compressor for building inference-optimized models from those trained with DL frameworks, and the OpenVINO toolkit for deploying high-performance, pre-trained DL inference models.
- Reference implementations and samples for specific use cases. Resources for data scientists include containers with pre-trained models and AI pipelines, reference toolkits, Cnvrg.io MLOps blueprints, and the Intel® Developer Cloud sandbox to test your workloads for free.
Pre-built Solutions to Accelerate Customer Time-to-Market
The ultimate value of this E2E hardware and software performance and productivity is demonstrated by Intel’s partners. They offer AI-ready solutions built on the AI Platform, choosing it because it enables them to run the entire E2E AI pipeline and general-purpose workload while also complying with their SLA using one development environment, from workstations to servers.
The Intel® Solutions Marketplace offers components, systems, services, and solutions by hundreds of Intel partners that feature Intel® technologies across dozens of industries and use cases.
Putting it All Together: Hardware, Software & Ecosystem Considerations for an AI Everywhere Future
With the shift of processor portfolios from being hardware-led to being software-defined and silicon-enhanced, more of the innovation is pulled-through to enable developers. The increased performance and developer productivity that Intel delivers through hardware, open software, and ecosystem engagement leads to earlier market readiness and accelerated product life cycles. This is especially critical in a fast-evolving field such as AI.
Let’s see how this plays out with a real-world use case involving transfer learning and inference and how the performance compares to competitor hardware options.
Use Case: Transfer Learning & Inference on Intel Xeon vs NVIDIA
Intel AMX, together with the software optimizations referenced above, accelerate deep learning models up to 10x1 and have demonstrated acceleration of E2E workloads up to 6.7x3.
In this example, Intel used the following software:
- PyTorch
- Trained Hugging Face’s BERT large language model
- SigOpt hyperparameter automation tool
- Intel® Neural Compressor, an automation tool for optimizing model precision, accuracy, and efficiency
Results:
- Using SigOpt, a single Intel Xeon SP node was fine-tuned in 20 minutes compared to 7 minutes with the NVIDIA A100 GPU. (Fine tuning is a technique in which the final layers of a model are customized using the customers data.)
- Using PyTorch and Intel Neural Compressor, Intel accelerated the inference pipeline 5.7x4 from 3rd Gen Xeon, 1.3x5 faster than NVIDIA A10.
- For even more examples and performance data, refer to the Intel AI performance page.
Takeaway: Using industry frameworks, thousands of pretrained models, and ecosystem tools, Intel enables the most cost effective and ubiquitous way to train via fine tuning and transfer learning on Intel® Xeon® processors.
![]()
3 Components for a Performant, Universal AI Platform
When measuring an entire pipeline, performance is very different than a narrow focus on dense DL models. The results suggest that the best kind of acceleration to build and deploy AI everywhere is a flexible, general-purpose CPU with the DL performance of a GPU with optimized E2E software, built with a ubiquitous AI platform:
- At the center of this platform is the Intel Xeon Scalable processor, which is the best for general-purpose compute and can also run every AI code across the ever-changing functions of the data science pipeline.
- The processors are complemented by a performant and productive AI software suite built on a unified oneAPI programming model, enabling every developer to infuse every application with AI.
- An extensive ecosystem of pre-built partner solutions on top of a Xeon-based AI platform accelerates time-to-solution.
These three components form the basis of the universal AI platform, which can scale from workstation to data center to factory floor; enable data scientists and application engineers to build and deploy AI everywhere; and unleash limitless data insights to solve our biggest challenges.
Product and Performance Information: 1,2,4 PyTorch Model Performance Configurations: 8480+: 1-node, pre-production platform with 2x Intel Xeon Platinum 8480+ on Archer City with 1024 GB (16 slots/ 64GB/ DDR5-4800) total memory, ucode 0x2b0000a1, HT on, Turbo on, CentOS Stream 8, 5.15.0, 1x INTEL SSDSC2KW256G8 (PT)/Samsung SSD 860 EVO 1TB (TF); 8380: 1-node, 2x Intel Xeon Platinum 8380 on M50CYP2SBSTD with 1024 GB (16 slots/ 64GB/ DDR4-3200) total memory, ucode 0xd000375, HT on, Turbo on, Ubuntu 22.04 LTS, 5.15.0-27-generic, 1x INTEL SSDSC2KG960G8; Framework:https://github.com/intelinnersource/frameworks.ai.pytorch.privatecpu/tree/d7607bdd983093396a70713344828a989b766a66;Modelzoo: https://github.com/IntelAI/models/tree/spr-launch-public, PT:1.13, IPEX: 1.13, OneDNN: v2.7; test by Intel on 10/24/2022. PT: NLP BERT-Large: Inf: SQuAD1.1 (seq len=384), bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,56, amx bf16=1,16, amx int8=1,56, Trg: Wikipedia 2020/01/01 ( seq len =512), bs:fp32=28, amx bf16=56 [1 instance, 1socket] PT: DLRM: Inference: bs=n [1socket/instance], bs: fp32=128, amx bf16=128, amx int8=128, Training bs:fp32/amx bf16=32k [1 instance, 1socket], Criteo Terabyte Dataset PT: ResNet34: SSD-ResNet34, Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,112, amx bf16=1,112, amx int8=1,112, Training bs:fp32/amx bf16=224 [1 instance, 1socket], Coco 2017 PT: ResNet50: ResNet50 v1.5, Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,64, amx bf16=1,64, amx int8=1,116, Training bs: fp32,amx bf16=128 [1 instance, 1socket], ImageNet (224 x224) PT: RNN-T Resnext101 32x16d, Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,64,amxbf16=1,64,amxint8=1,116,ImageNet PT: ResNext101: Resnext101 32x16d, bs=n [1socket/instance], Inference: bs: fp32=1,64, amx bf16=1,64, amx int8=1,116 PT: MaskRCNN: Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,112, amx bf16=1,112, Training bs:fp32/amx bf16=112 [1 instance, 1socket], Coco 2017 Inference: Resnet50 v1.5: ImageNet (224 x224), SSD Resnet34: coco 2017 (1200 x1200), BERT Large: SQuAD1.1 (seq len=384), Resnext101: ImageNet, Mask RCNN: COCO 2017, DLRM: Criteo Terabyte Dataset, RNNT: LibriSpeech. Training: Resnet50 v1.5: ImageNet (224 x224), SSD Resnet34: COCO 2017, BERT Large: Wikipedia 2020/01/01 ( seq len =512), DLRM: Criteo Terabyte Dataset, RNNT: LibriSpeech, Mask RCNN: COCO 2017.480: 1-node, pre-production platform with 2x Intel® Xeon® Platinum 8480+ on Archer City with 1024 GB 3 6.7X Inference Speed-up: 8480 (1-node, pre-production platform with 2x Intel® Xeon® Platinum 8480+ on Archer City with 1024 GB (16 slots/ 64GB/ DDR5-4800) total memory, ucode 0x2b000041) , 8380 (1-node, 2x Intel® Xeon® Platinum 8380 on Whitley with 1024 GB (16 slots/ 64GB/ DDR4-3200) total memory, ucode 0xd000375) HT off, Turbo on, Ubuntu 22.04.1 LTS, 5.15.0-48-generic, 1x INTEL SSDSC2KG01, BERT-large-uncased (1.3GB : 340 Million Param) https://huggingface.co/bert-large-uncased, IMDB (25K for fine-tuning and 25K for inference): 512 Seq Length – https://analyticsmarketplace.intel.com/find-data/metadata?id=DSI-1764; SST-2 (67K for fine-tuning and 872 for inference): 56 Seq Length – , FP32, BF16,INT8 , 28/20 instances, https://pytorch.org/, PyTorch 1.12, IPEX 1.12, Transformers 4.21.1, MKL 2022.1.0, test by Intel on 10/21/2022. 5 NVIDIA Configuration details: 1x NVIDIA A10: 1-node with 2x AMD Epyc 7763 with 1024 GB (16 slots/ 64GB/ DDR4-3200) total memory, HT on, Turbo on, Ubuntu 20.04,Linux 5.4 kernel, 1x 1.4TB NVMe SSD, 1x 1.5TB NVMe SSD; Framework: TensorRT 8.4.3; Pytorch 1.12, test by Intel on 10/24/2022. 6 1.9X average ML performance vs AMD: Geomean of kmeans-fit, kmeans-infer, ridge_regr-fit, ridge_regr-infer, linear_regr-fit, linear_regr-infer, logistic_regr-fit, logistic_regr-infer, SVC-fit, SVC-infer, dbscan-fit, kdtree_knn-infer, elastic-net-fit, elastic-net-infer, train_test_split-fit, brute_knn-infer. 8480+: 1-node, pre-production platform with 2x Intel(R) Xeon(R) Platinum 8480+ on ArcherCity with 1024 GB (16 slots/ 64GB/ DDR5-4800) total memory, ucode 0xab0000a0, HT OS disabled, Turbo on, CentOS Stream 8, 4.18.0-408.el8.x86_64, scikit-learn 1.0.2, icc 2021.6.0, gcc 8.5.0, python 3.9.7, conda 4.14.0, oneDAL master(a8112a7), scikit-learn-intelex 2021.4.0, scikit-learn_bench master (3083ef8), test by Intel on 10/24/2022. 7763: 1-node, 2x AMD EPYC 7763 on MZ92-FS0-00 with 1024 GB (16 slots/ 64GB/ DDR4-3200) total memory, ucode 0xa001144, HT OS disabled, Turbo on, Red Hat Enterprise Linux 8.4 (Ootpa), 4.18.0-408.el8.x86_64, scikit-learn 1.0.2, icc 2021.6.0, gcc 8.5.0, python 3.9.7, conda 4.14.0, oneDAL master(a8112a7), scikit-learn-intelex 2021.4.0, scikit-learn_bench master (3083ef8), test by Intel on 9/1/2022.