Intel® Neural Compressor
Speed Up AI Inference without Sacrificing Accuracy
Deploy More Efficient Deep Learning Models
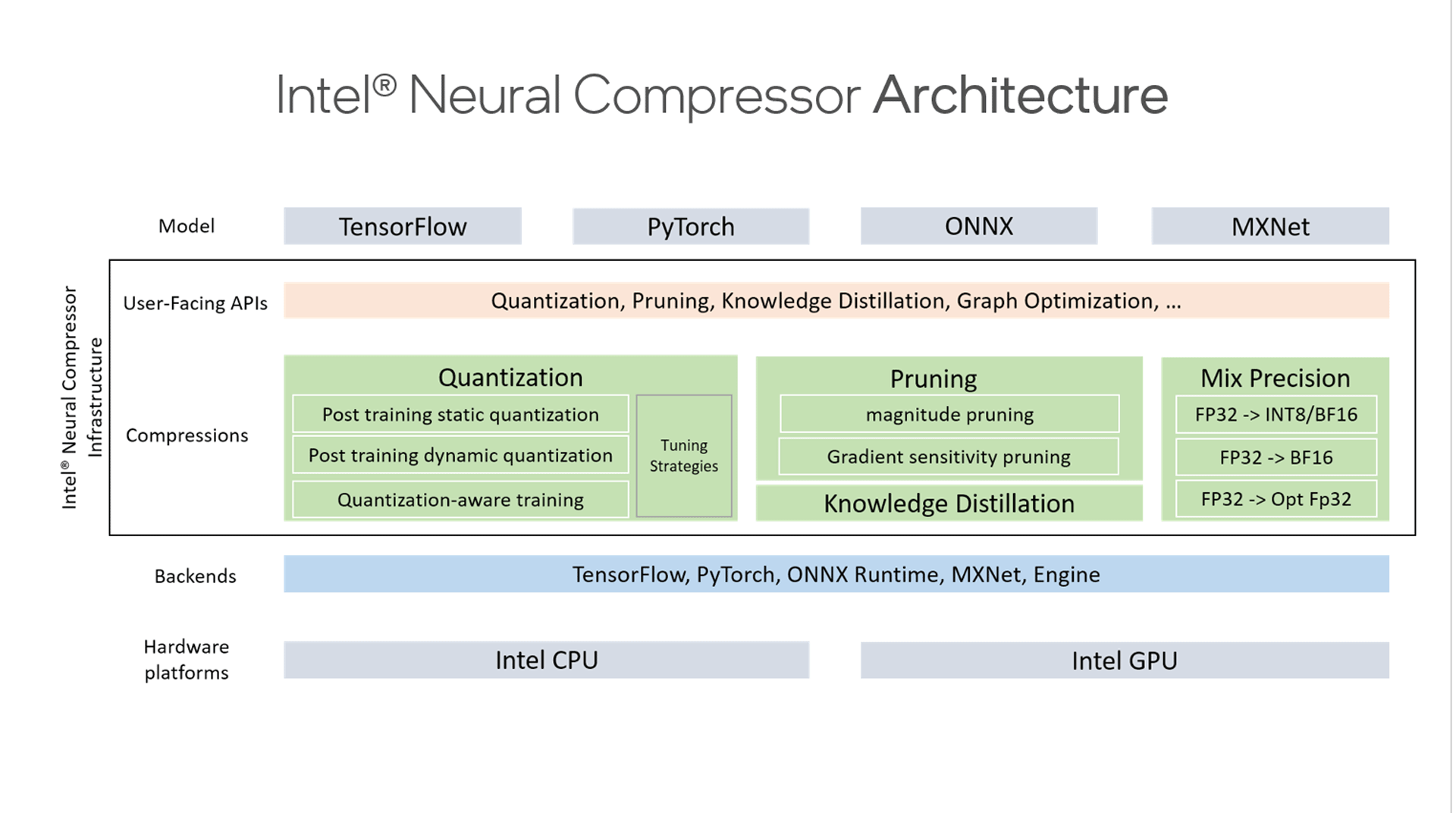
Intel® Neural Compressor performs model optimization to reduce the model size and increase the speed of deep learning inference for deployment on CPUs or GPUs. This open source Python* library automates popular model optimization technologies, such as quantization, pruning, and knowledge distillation across multiple deep learning frameworks.
Using this library, you can:
- Converge quickly on quantized models though automatic accuracy-driven tuning strategies.
- Prune the least important parameters for large models.
- Distill knowledge from a larger model to improve the accuracy of a smaller model for deployment.
- Get started with model quantization with one-click analysis and code insertion.
Intel Neural Compressor is part of the end-to-end suite of Intel® AI and machine learning development tools and resources.
Download the AI Tools
Intel Neural Compressor is available in the AI Tools Selector, which provides accelerated machine learning and data analytics pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Download the Stand-Alone Version
A stand-alone download of Intel Neural Compressor is available. You can download binaries from Intel or choose your preferred repository.
Develop in the Cloud
Build and optimize oneAPI multiarchitecture applications using the latest Intel-optimized oneAPI and AI tools, and test your workloads across Intel® CPUs and GPUs. No hardware installations, software downloads, or configuration necessary.
Help Intel Neural Compressor Evolve
This open source component has an active developer community. We welcome you to participate.
Features
{kind=link}
Model Optimization Techniques
- Quantize activations and weights to int4, int8, bfloat16, or a mixture of FP32, bfloat16, and int8 to reduce model size and to speed inference while minimizing precision loss. Quantize during training, posttraining, or dynamically, based on the runtime data range.
- Prune parameters that have minimal effect on accuracy to reduce the size of a model. Configure pruning patterns, criteria, and schedule.
- Automatically tune quantization and pruning to meet accuracy goals.
- Distill knowledge from a larger model (“teacher”) to a smaller model (“student”) to improve the accuracy of the compressed model.
- Customize quantization with advanced techniques such as SmoothQuant, layer-wise quantization, and weight-only quantization (WOQ).
- Visualize and diagnose quantization accuracy loss with Neural Insights.
- Schedule and manage distributed model optimization tasks with Neural Solution.
Automation
- Quantize with one click using the Neural Coder plug-in for JupyterLab and Microsoft Visual Studio* code, which automatically benchmarks approaches to optimize performance.
- Achieve objectives with expected accuracy criteria using built-in strategies to automatically apply quantization techniques to operations.
- Combine multiple model optimization techniques with one-shot optimization orchestration.
Interoperability
- Optimize models created with PyTorch*, TensorFlow*, or Open Neural Network Exchange (ONNX*) Runtime.
- Configure model objectives and evaluation metrics without writing framework-specific code.
- Export optimized models in PyTorch, TensorFlow, or ONNX for interoperability with other frameworks.
- Validate quantized ONNX models for deployment to third-party hardware architectures via ONNX Runtime.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Case Studies
Palo Alto Networks Reduces Inference Latency by 6x
To deliver the required response speed for multiple cybersecurity models, Palo Alto Networks quantized their models to int8, taking advantage of advanced instruction sets and accelerators.
Sustainable AI with Intel®-Optimized Software and Hardware
HPE Services applied Intel AI software together with int8 post-training static quantization to reduce energy consumption by at least 68% across multiple experiments.
delphai* Accelerates Natural Language Processing Models for Search Engines
By quantizing its models to int8, delphai* accelerated inference speed without sacrificing accuracy, enabling the use of less costly CPU-based cloud instances.
Demonstrations
Quantize LLMs with SmoothQuant
Large language models (LLMs) tend to have large-magnitude outliers in certain activation channels. Learn how the SmoothQuant technique addresses this and how to use it to quantize a Hugging Face* Transformer model to 8-bit.
One-Click PyTorch* Model Optimization
Neural Coder is a code-free solution that automatically enables quantization algorithms in a PyTorch model script and evaluates for the best model performance. See how to use it for static and dynamic quantization in PyTorch.
Quantize Large Language Models with Just a Few Lines of Code
Quantizing LLMs to int4 reduces model size up to 8x, speeding inference. Learn how to get started applying weight-only quantization (WOQ) and see the accuracy impact on popular LLMs.
One-Click Acceleration of Hugging Face* Transformers with Neural Coder
Optimum for Intel is an extension to Hugging Face* transformers that provides optimization tools for training and inference. Neural Coder automates int8 quantization using the API for this extension.
Distill and Quantize BERT Text Classification
Perform knowledge distillation of the BERT base model and quantize to int8 using the Stanford Sentiment Treebank 2 (SST-2) dataset. The resulting BERT-Mini model performs inference up to 16x faster.
Quantization in PyTorch Using Fine-Grained FX
Convert an imperative model into a graph model, and perform dynamic quantization, quantization-aware training, or post training static quantization.
Documentation & Code Samples
Code Samples
- Get Started
- Model Optimization: TensorFlow | PyTorch | ONNX Runtime
- Get Started with Neural Coder
- Accelerate Stable Diffusion with Post-Training Quantization
- Quantizing a DistilBERT Humor Natural Language Processing (NLP) Model
- Optimize VGG19 Model Inference on 4th Gen Intel Xeon Scalable Processors
Training & Tutorials
Get Started with AI Model Optimization
Perform Dynamic Quantization on a Pretrained PyTorch Model
Compress the Transformer: Optimize Your DistilBERT Models
Quantize During Fine-Tuning with Hugging Face Optimum
Perform Structured Pruning on Transformer-Based Models
Diagnose Quantization Accuracy Loss with Neural Insights
Get Started with Neural Solution Model Optimization-as-a-Service
Specifications
Processor:
- Intel Xeon processor
- Intel Xeon CPU Max Series
- Intel® Core™ processor
- Intel® Data Center GPU Flex Series
- Intel® Data Center GPU Max Series
Operating systems:
- Linux*
- Windows*
Language:
- Python
Get Help
Your success is our success. Access this support resource when you need assistance.
For additional help, see the general Support.
Related Products
Stay Up to Date on AI Workload Optimizations
Sign up to receive hand-curated technical articles, tutorials, developer tools, training opportunities, and more to help you accelerate and optimize your end-to-end AI and data science workflows. Take a chance and subscribe. You can change your mind at any time.