Text generation is the process of generating text by an AI system that resembles human-written text patterns and styles. Image generation is the task of creating realistic images from scratch or based on an input dataset. They have become increasingly popular as these generators offer a novel way to create text and images by revolutionizing content creation and manipulation paradigms. Both text and image generation involve training AI models on large datasets of text or image-text pairs to learn everything, including patterns, grammar, contextual information, colors, and what different objects look like. These models then use this learned knowledge to generate new text and images based on given prompts or conditions.
In this article, we demonstrate how to perform text and image generation on Intel® hardware using Intel® Extension for PyTorch*.
Intel® Extension for PyTorch* Features Improve Performance of Text and Image Generation
The PyTorch extension from Intel extends PyTorch with up-to-date features and optimizations for an extra performance boost on Intel hardware. The extension can be loaded as a Python* module or linked as a C++ library. Python users can enable it dynamically by importing intel_extension_for_pytorch.
Learn how to install Intel Extension for PyTorch as a stand-alone component or get it as part of the AI Tools.
For text and image generation, the following highlights features in the 2.2 and 2.1 releases that developers can use to enhance their performance on large language and generative AI models:
- Large Language Model (LLM) optimizations: Intel® Extension for PyTorch* provides optimizations for LLMs in this new release. On the operator level, we provide a highly efficient GEMM kernel to speed up linear layers and customized operators to reduce the memory footprint. A new API function, ipex.llm.optimize, is designed to optimize transformer-based models within front-end Python modules, with a particular focus on LLMs. It provides optimizations model-wise and content-generation-wise. This API replaces the previous ipex.optimize_transformers to bring a more consistent LLM experience and performance.
You just need to invoke the ipex.llm.optimize function instead of the ipex.optimize function to apply all optimizations transparently. For more details, see Large Language Model Optimizations Overview.
A typical use of this new feature is:
where dtype is “bfloat16” and deployment_mode is True by default.import torch import intel_extension_for_pytorch as ipex model = … model = ipex.llm.optimize(model.eval(), dtype=dtype, inplace=True, deployment_mode=deployment_mode)
- torch.compile back-end optimization with PyTorch Inductor (experimental): We optimized the extension to use PyTorch Inductor’s capability when working as a back end of torch.compile. It also includes custom fusions at the FX graph level, such as migrating existing TorchScript-based fusion kernels in Intel Extension for PyTorch to inductor and pattern-based fusions to achieve peak performance. For more details, see the GitHub* documentation.
Use is as follows:model = torch.compile(model, backend=’ipex’)
- Performance optimization of static quantization for dynamic shapes: Static quantization performance for dynamic shapes is optimized in this new release. The use is the same as the workflow of running static shapes while inputs of variable shapes could be provided during runtime.
- New capability for users to auto-tune a good quantization recipe for running SmoothQuant int8 with good accuracy: SmoothQuant is a popular method to improve the accuracy of int8 quantization, and this API allows automatic global and layer-by-layer alpha tuning. For more details, see the SmoothQuant Recipe Tuning API Introduction.
Optimize Text Generation
Optimizing text generation means improving the latency and throughput of outputting text from the prompt by enhancing the user experience for a wide range of applications. Large language models (LLMs) are popular for these text generation applications. Intel Extension for PyTorch provides inference benchmarking scripts to improve GPT-J, LLaMA, GPT-NeoX, OPT, Falcon, and other large language models to run on Intel CPUs. We recommend using 4th generation Intel® Xeon® Scalable processors or newer to use the Intel® Advanced Matrix Extensions (Intel® AMX) instruction set for bfloat16 (BF16) and integer8 (int8) operations. These scripts can run with a single instance and in distributed use cases with DeepSpeed. DeepSpeed is an open source deep learning optimization software suite by Microsoft* that enables scale and speed for distributed training and inference. Low precision data types are supported on select models with the use of static quantization and weight-only quantization.
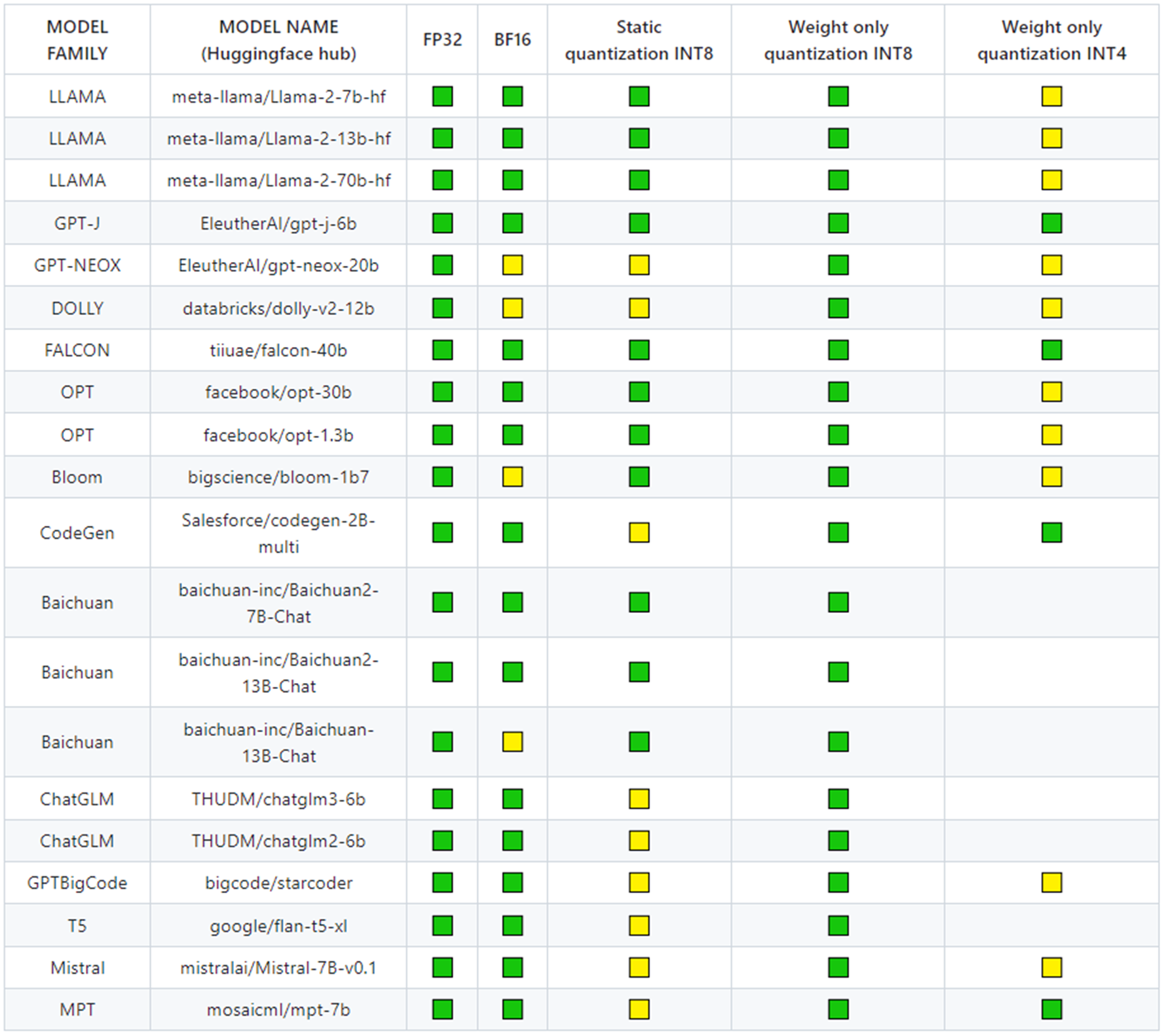
Figure 1. Supported model list on CPUs with Intel Extension for PyTorch v2.2
A Dockerfile is provided to set up the environment. It installs Intel Extension for PyTorch 2.2 and sets up environment variables for optimal performance on Intel Xeon CPUs. After the Docker* image is compiled, start a container. The /root/llm directory will contain the example scripts. Alternatively, you can create a conda environment and run the env_setup.sh script in the tools folder.
To optimize runtime performance on Intel Xeon Scalable processors, certain environment variables need to be set including:
- KMP_BLOCKTIME=1
- KMP_TPAUSE=0
- KMP_FORKJOIN_BARRIER_PATTERN=dist,dist
- KMP_PLAIN_BARRIER_PATTERN=dist,dist
- KMP_REDUCTION_BARRIER_PATTERN=dist,dist
- LD_PRELOAD to include the Standard C++, OpenMP*, and TCMalloc libraries
An automation script env_activate.sh is available for setting these environment variables as well as others in the example directory /root/llm/tools. It will also source the Intel® oneAPI Collective Communications Library (oneCCL) environment variables.
For more information about setting these environment variables, in the GitHub documentation for Intel Extension for PyTorch, see the Performance Tuning Guide.
After setting up the environment, the run.py script can be run with customized input arguments to run text generation in bfloat16, int8, and int4. For example, if you are running with a 56-core 4th generation Intel Xeon Scalable Processor and want to run text generation with the 7B LLaMA2 model, for benchmarking or accuracy results, follow these instructions.
There are preset commands to run with certain configurations for a single instance, including FP32, bfloat16, static quantization (int8), and weight-only quantization (int8/int4).
To better understand how the optimizations are made, you can look at the run_generation.py script in the single_instance folder. The folder also contains scripts to run quantization in int8 and int4, and then benchmark using the resulting quantized models. While quantization can reduce the memory footprint of the model and speed up inference, the tradeoff is accuracy, especially in int4.
The following code shows an example of LLM optimizations for FP32 or BF16 from Intel Extension for PyTorch, and run_generation.py follows this same flow.
import torch
import intel_extension_for_pytorch as ipex
import transformers
model= transformers.AutoModelForCausalLM(model_name_or_path).eval()
dtype = torch.float # or torch.bfloat16
model = ipex.llm.optimize(model, dtype=dtype)
model.generate(YOUR_GENERATION_PARAMS)
Additional examples can be found at the LLM optimization API.
ipex.llm.optimize() is a new API function featured on Intel Extension for PyTorch v2.2. It is equivalent to ipex.optimize() but is specific to transformer models. The models mentioned in Figure 1 are optimized for single instances using this new method. You can try using ipex.llm.optimize() on other transformer models from Hugging Face* not listed in Figure 1, but the performance benefits are not guaranteed. Other large language models may be supported in the future.
To run distributed inference with multiple devices using DeepSpeed with the AutoTP method, follow the example commands. You can read more about tensor parallelism in this paper. There are also scripts to run using DeepSpeed for distributed performance in the distributed folder.
To run on Intel GPUs, use Intel Extension for PyTorch version 2.1.20+xpu. The Text Generation example supports Max Series 1550 and 1100 on a variety of models, including LLAMA2, GPT-J, OPT, and Bloom. Note that the list of supported models are different from those for CPU, but more models will be supported in the future. The setup is similar to that for CPU, though it is worth mentioning additional environment variables need to be set, including DPCPP_ROOT, ONEMKL_ROOT, ONECCL_ROOT, and SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS. The values are specified in the README.
Currently, only Float16 (FP16) and weight-only quantization to int4 are supported. You can follow the instructions to run with a single instance. Here is an example of running inference with the 7-billion parameter LLaMA2 on GPU in FP16 with 1024 input tokens and 128 output tokens:
python -u run_generation.py --benchmark -m meta-llama/Llama-2-7b-hf --num-beams 4 --num-iter 10 --batch-size 1 --input-tokens 1024 --max-new-tokens 128 --device xpu --ipex --dtype float16 --token-latency
The argument to pay attention to is the device where we specify xpu in this example.
Optimize Image Generation
Generating good quality images using deep learning techniques is especially important to explore new possibilities in artistic creation. One of the most popular models for generating images is Stable Diffusion*. Starting with Intel Extension for PyTorch v2.1, there are optimizations on models such as Stable Diffusion v1.5 from a Hugging Face StableDiffusionPipeline object from Hugging Face contains three models – text encoder, UNet, and a Variational Autoencoder (VAE). Traditionally, ipex.optimize() is used to optimize each of these models. Now, torch.compile with the Intel Extension for PyTorch back end can be used in conjunction with ipex.optimize() for further improvement. This can be done by setting backend=”ipex” as an input argument to torch.compile() along with the model itself.
Use the following steps in your code. Assume the Stable Diffusion model is loaded into model, and the Intel Extension for PyTorch library is imported as ipex.
model = ipex.optimize(model.eval(), dtype=torch.bfloat16, weights_prepack=False)
ipex._set_compiler_backend("torchscript")
model = torch.compile(model, backend=”ipex”)
Demo
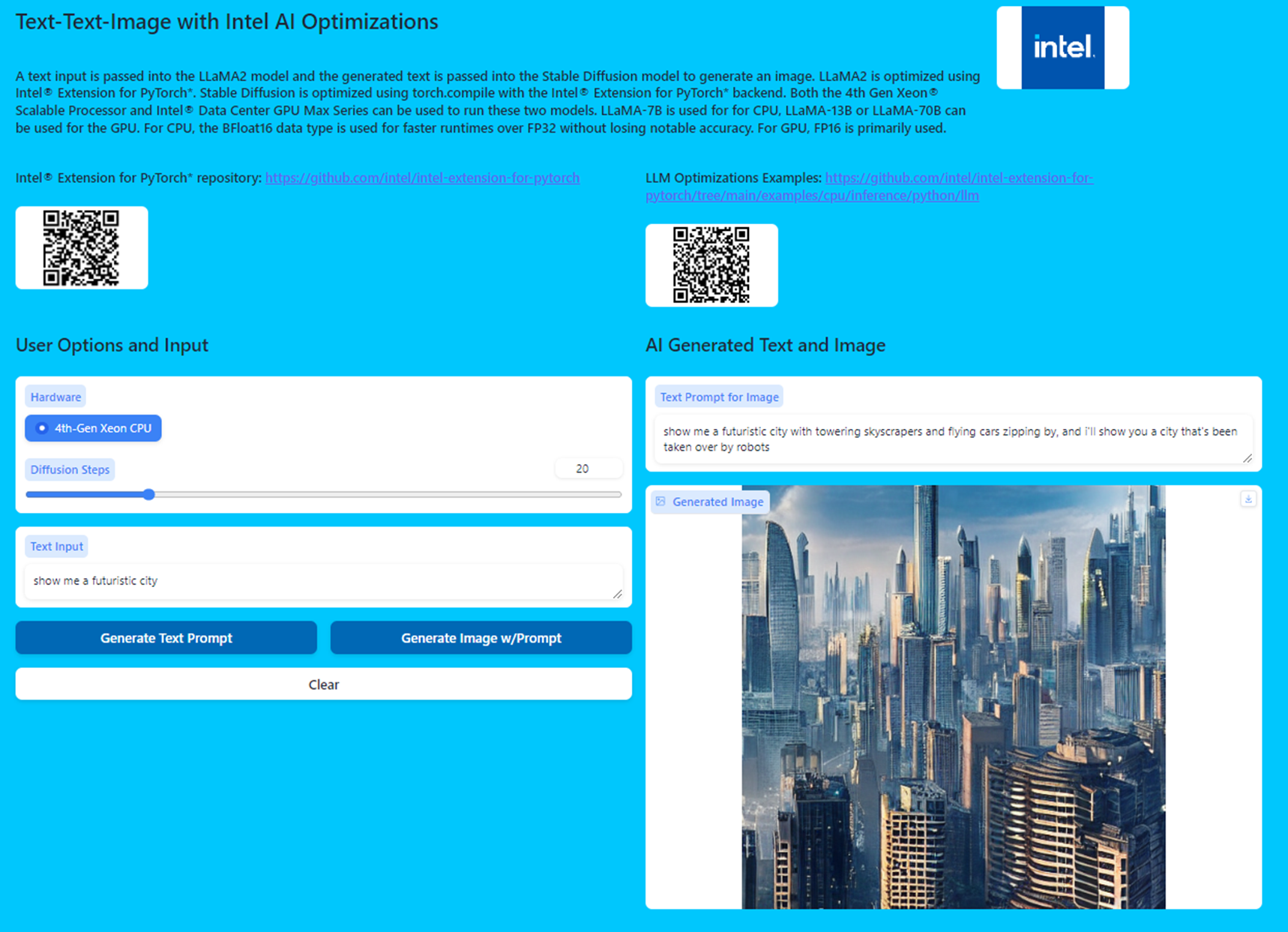
This demo showcases text generation using LLaMA2 and image generation using Stable Diffusion with new performance features on Intel Extension for PyTorch. To make it interesting, the output text of LLaMA2 model is used as the input for the Stable Diffusion model. LLaMA2 is optimized using ipex.llm.optimize() and Stable Diffusion is optimized using ipex.optimize() and torch.compile() with the ipex back end. This demo is implemented on an AWS* M7i.16x.large instance, which is powered by a 4th gen Intel Xeon Scalable processor with 32 cores. Notice how the text and image can be generated in seconds on a CPU.
Following is an image of the web UI with sample text input, the generated text, and generated image:
What’s Next?
Download and try the AI Tools and Intel Extension for PyTorch for yourself to build various end-to-end AI applications. We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
For more details about 4th generation Intel Xeon Scalable processors, visit Intel's AI Solution Platform portal where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.