Intel® oneAPI Deep Neural Network Library
Increase Deep Learning Framework Performance on CPUs and GPUs
Develop Faster Deep Learning Frameworks and Applications
The Intel® oneAPI Deep Neural Network Library (oneDNN) provides highly optimized implementations of deep learning building blocks. With this open source, cross-platform library, deep learning application and framework developers can use the same API for CPUs, GPUs, or both—it abstracts out instruction sets and other complexities of performance optimization.
Using this library, you can:
- Improve performance of frameworks you already use, such as OpenVINO™ toolkit, AI Tools from Intel, PyTorch*, and TensorFlow*.
- Develop faster deep learning applications and frameworks using optimized building blocks.
- Deploy applications optimized for Intel CPUs and GPUs without writing any target-specific code.
Download as Part of the Toolkit
oneDNN is included as part of the Intel® oneAPI Base Toolkit, which is a core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.
Download the Stand-Alone Version
A stand-alone download of oneDNN is available. You can download binaries from Intel or choose your preferred repository.
Develop in the Cloud
Build and optimize oneAPI multiarchitecture applications using the latest Intel-optimized oneAPI and AI tools, and test your workloads across Intel® CPUs and GPUs. No hardware installations, software downloads, or configuration necessary.
Help oneDNN Evolve
oneDNN is part of the oneAPI industry standards initiative. We welcome you to participate.
{kind=link}
Features
Automatic Optimization
- Use existing deep learning frameworks
- Develop platform-independent deep learning applications and deploy your instruction set architecture (ISA) with automatic detection of and optimization.
Network Optimization
- Identify performance bottlenecks using Intel® VTune™ Profiler
- Use automatic memory format selection and propagation based on hardware and convolutional parameters
- Fuse primitives with operations applied to the primitive’s result, for instance, Conv+ReLU
- Quantize primitives from FP32 to FP16, bf16, or int8 using Intel® Neural Compressor
Optimized Implementations of Key Building Blocks
- Convolution
- Matrix multiplication
- Pooling
- Batch normalization
- Activation functions
- Recurrent neural network (RNN) cells
- Long short-term memory (LSTM) cells
Abstract Programming Model
- Primitive: Any low-level operation from which more complex operations are constructed, such as convolution, data format reorder, and memory
- Memory: Handles to memory allocated on a specific engine, tensor dimensions, data type, and memory format
- Engine: A hardware processing unit, such as a CPU or GPU
- Stream: A queue of primitive operations on an engine
Benchmarks
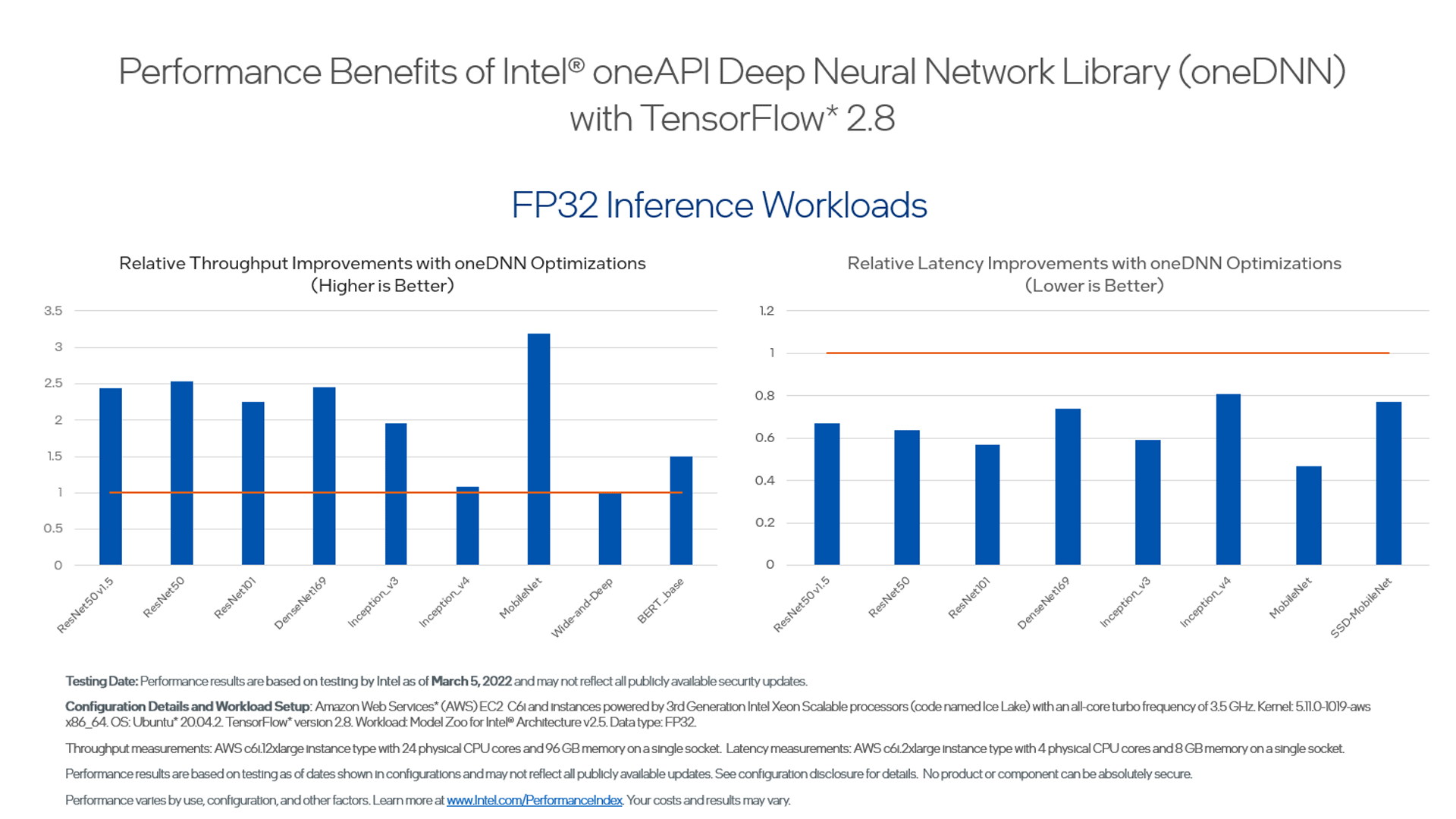{kind=link}
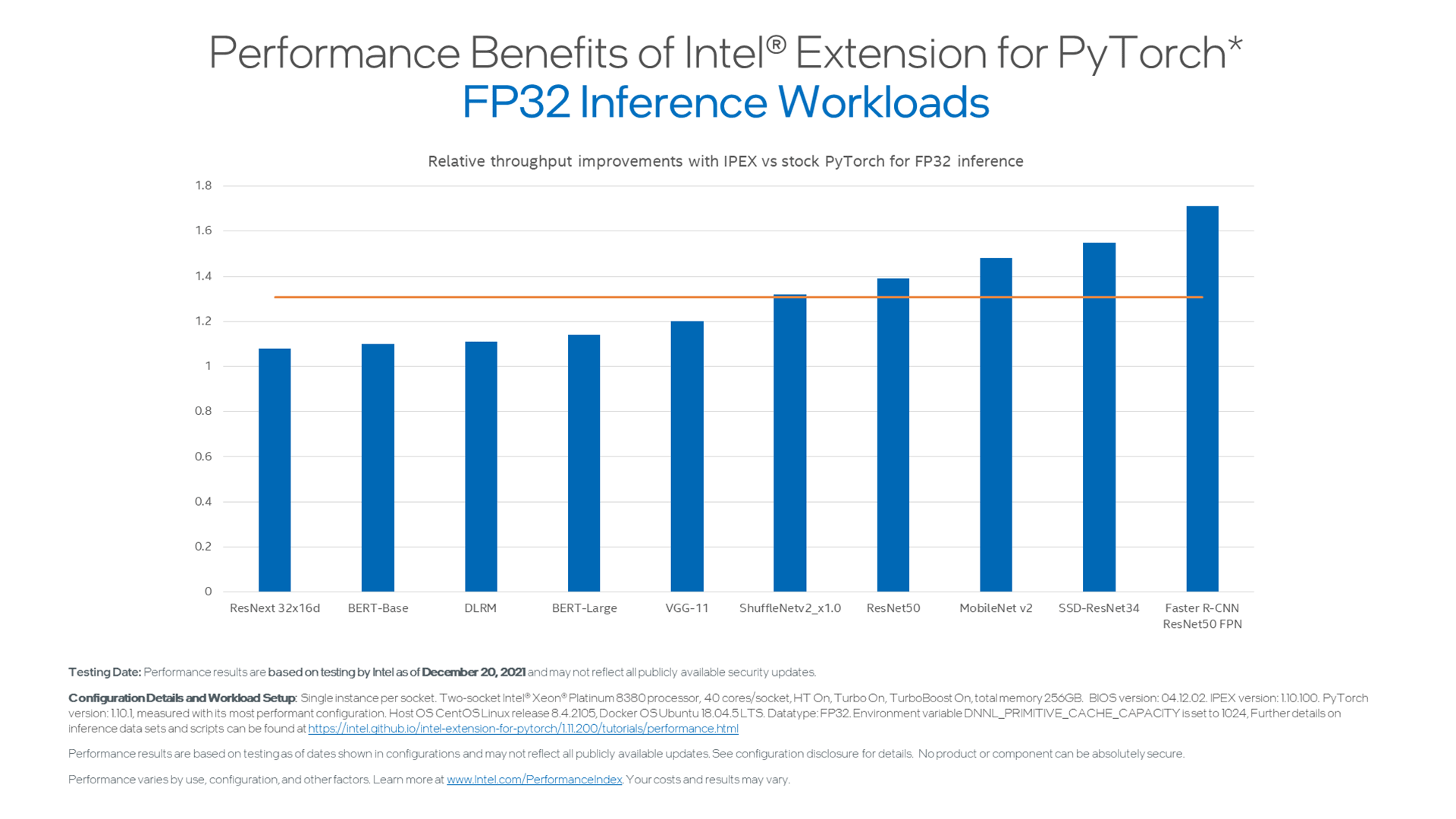{kind=link}
Case Studies
Preparing for Aurora: Ensuring the Portability of Deep Learning Software to Explore Fusion Energy
Argonne National Laboratory ported FusionDL, a collection of machine learning models and implementations in multiple frameworks, including TensorFlow and PyTorch optimized by oneDNN, to the Aurora exascale supercomputer.
Digital Transformation in Tough Times: Four Innovative Examples Powered by Data, AI, and Flexible Infrastructure
Large datasets and AI are applied securely and reliably to address challenges with the supply chain, utilities, healthcare, and COVID-19 risk management for returning to work while preserving privacy.
Demonstrations
Leverage Deep Learning Optimizations from Intel in TensorFlow*
oneDNN optimizations are available in TensorFlow, which enables developers to seamlessly benefit from Intel's optimizations.
Accelerate Bfloat16-based PyTorch*
Engineers from Intel and Facebook* introduce the latest software advancements added to Intel® Extension for PyTorch* on top of PyTorch and oneDNN.
News
TensorFlow and oneDNN in Partnership
Google* and Intel have been collaborating closely and optimizing TensorFlow to fully use new hardware features and accelerators.
Software AI Accelerators: AI Performance Boost for Free
Accelerate the deep learning framework you already use, such as TensorFlow, PyTorch, or Apache MXNe*, with oneDNN.
Documentation & Code Samples
Code Samples
Get Started
Learn how to configure and compile oneDNN applications using prebuilt oneDNN binaries, and how to run these applications on different Intel architectures.
oneDNN with SYCL* Interoperability
Use this code sample to learn about programming for Intel CPU and GPU with SYCL* extensions API in oneDNN.
Tutorials
A oneDNN Library for Convolutional Neural Network (CNN) Inference (FP32)
Learn how oneDNN helps to build a neural network topology for forward-pass inference that implements topology layers as numbered primitives.
Use these guided samples on a Jupyter* Notebook to examine oneDNN functionality for developing deep learning applications and neural networks, optimized for Intel CPUs and GPUs.
How to work with code samples:
Training
Understanding oneDNN
AI Model Performance
Specifications
Processors:
- Intel Atom® processors with Intel® Streaming SIMD Extensions
- Intel® Core™ processors
- Intel® Xeon® processors
GPUs:
- Intel® Processor Graphics Gen9 and above
- Iris® graphics
- Intel® Data Center GPUs
- Intel® Arc™ A-series graphics
Host & target operating systems:
- Linux*
- Windows*
- macOS*
Languages:
- SYCL
Note Must have Intel oneAPI Base Toolkit installed
- C and C++
Compilers:
- Intel® oneAPI DPC++/C++ Compiler
- Clang*
- GNU C++ Compiler*
- Microsoft Visual Studio*
- LLVM* for Apple*
Threading runtimes:
- Intel® oneAPI Threading Building Blocks
- OpenMP*
- SYCL
For more information, see the system requirements.
Get Help
Your success is our success. Access these resources when you need assistance.
For additional help, see oneAPI Support.
Stay Up to Date on AI Workload Optimizations
Sign up to receive hand-curated technical articles, tutorials, developer tools, training opportunities, and more to help you accelerate and optimize your end-to-end AI and data science workflows. Take a chance and subscribe. You can change your mind at any time.