Intel® Hardware and Software Stack for Big Data
Alexander Andreev, machine learning engineer, and Egor Smirnov, software engineering manager, Intel Corporation
@IntelDevTools
The amount of data humans produce every day is growing exponentially and so is the need for high-performance, scalable algorithms to process and extract benefit from all this data. Intel puts a lot of effort into building effective data analytics tools for our platforms by optimizing not only hardware, but also software. In recent years, Intel has built a powerful data analytics and machine-learning software and hardware stack that includes both optimized frameworks1 and libraries2.
From the hardware side, high performance and scalability are provided by Intel® Xeon® Scalable Processors (the 2nd generation also contains Intel® Deep Learning Boost, Intel® FPGAs, and Intel® Movidius Neural Compute Stick [NCS]).
scikit-learn* Optimized by Intel and Intel® Data Analytics Acceleration Library
One of the Intel®-optimized frameworks for classic machine-learning algorithms, scikit-learn*3, is part of the Intel® Distribution for Python*. scikit-learn uses the Intel® Data Analytics Acceleration Library (Intel® DAAL) underneath to obtain high performance on Intel® architectures. Intel DAAL is an open-source4 data analytics library optimized for Intel® architectures ranging from mobile (Intel Atom® processors) to data centers (Intel® Xeon® processors). Intel DAAL provides C++, Java*, and Python* APIs. It also provides the newly introduced Data Parallel C++ (DPC++), which is part of oneAPI, a unified programming model for effective development on different architectures (CPU, GPU, and others).
K-means is one of the accelerated machine-learning algorithms for scikit-learn in the Intel Distribution for Python.
The K-means Algorithm
K-means, a popular clustering algorithm, is used in astronomy, medicine, market segmentation, and many other areas. It’s one of the accelerated machine-learning algorithms implemented in Intel DAAL. K-means is both simple and powerful. Its objective is to split a set of N observations into K clusters. This is achieved by minimizing inertia (that is, the sum of squared Euclidean distances from observations to the cluster centers [centroids]). The algorithm is iterative, with two steps in each iteration:
- For each observation, compute the distance from it to each centroid, and then reassign each observation to the cluster with the nearest centroid.
- For each cluster, compute the centroid as the mean of observations assigned to this cluster.
Repeat these steps until one of the following happens:
- The number of iterations exceeds its predefined maximum.
- The algorithm converges (that is, the difference between two consecutive inertias is less than a predefined threshold).
Different initialization methods are used to get initial centroids for the first iteration. It can select random observations as initial centroids, or use more complex methods such as K-means++.5
Intel DAAL versus RAPIDS cuML on Distributed K-means
To show how well Intel DAAL accelerates K-means, we compared it to RAPIDS cuML, which claims to be 90x faster than CPU-based implementations6. We also compared cuML to scikit-learn from the Intel Distribution for Python, which uses Intel DAAL underneath.
From Amazon Elastic Compute Cloud* (Amazon EC2*)7, we used the following instances (nodes) to measure performance:
- Multiple (up to eight) Amazon EC2 c5.24xlarge instances with 2nd generation Intel Xeon Scalable processors
- One Amazon EC2 p3dn.24xlarge instance with eight NVIDIA* Tesla V100 GPUs
We chose the maximum number of c5.24xlarge instances to be eight because the cost per hour of eight c5.24xlarge instances is approximately the same as one p3dn.24xlarge instance. We used a synthetic dataset with 200 million observations, 50 columns, and 10 clusters, which is as much as the memory that NVIDIA Tesla V100 GPU can store. A similar dataset with 300 million observations instead of 200 caused a RAPIDS memory error (RMM_ERROR_OUT_OF_MEMORY). CPU-based systems can typically process much larger datasets. The code for dataset generation is shown in the Code Examples section at the end of this article.
We chose the same initialization method in all measured cases for a direct comparison, and we chose the float32 datatype since it gives sufficient accuracy and fits in memory.
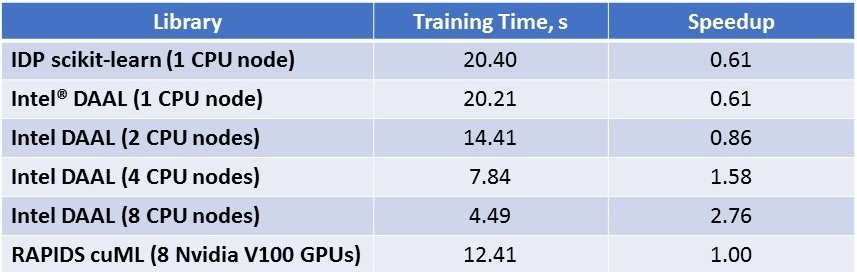
Figure 1 and Table 1 show that starting from four Intel Xeon Scalable processor nodes, Intel DAAL outperforms cuML on eight NVIDIA V100 GPUs. Even one node with two Intel Xeon Scalable processors is only 40 percent slower than eight NVIDIA Tesla V100 GPUs. Also, it can hold and process the whole dataset, while fewer than eight V100s cannot. scikit-learn and Intel DAAL on one CPU node show approximately the same results: The difference in training time is trivial, and due to Intel DAAL function call overhead.
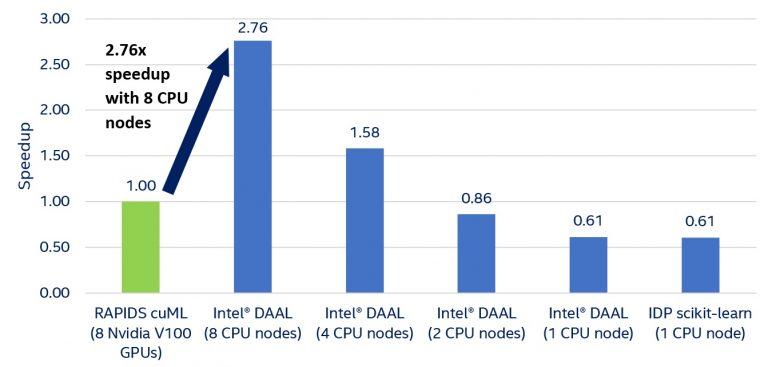
Figure 1. Speedup of K-means training with Intel DAAL
Table 1. K-means training time (in seconds) and speedup: comparison of scikit-learn, Intel DAAL, and RAPIDS cuML
The K-means algorithm converges to the same result for all measured cases. Inertia is 4×104. The scikit-learn and Intel DAAL examples are available in the Code Examples section. Moreover, we calculated the K-means training cost as the cost of instances on Amazon EC2 multiplied by the training time for eight Intel Xeon processor nodes and eight V100 GPUs, respectively.
k-means training cost ($) 
Figure 2 shows that using Intel DAAL with eight CPU nodes results in up to 2.64x reduction in K-means training cost.
Faster and Cheaper
On Amazon EC2, distributed K-means computations are 2.76x faster and 2.64x cheaper with Intel DAAL on eight Intel Xeon processor nodes than with RAPIDS cuML on eight NVIDIA Tesla V100 GPUs. Moreover, Intel Xeon processor-based instances can process larger datasets: Data that is easily processed on one node based on Intel Xeon processor causes “out of memory” errors on eight NVIDIA V100 GPUs. With Intel® Optane™ technology8, memory capacity increases to 4.5 TB per socket (9 TB per two-socket instance), while an NVIDIA DGX-2* has only 512 GB of GPU memory.
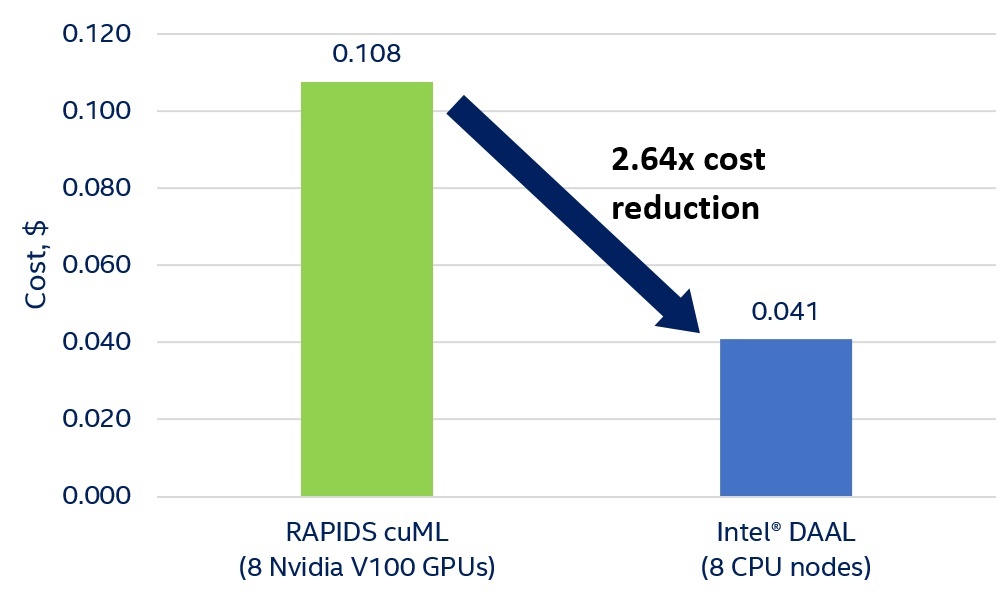
Figure 2. K-means training cost: 19 RAPIDS cuML on eight GPUs and Intel DAAL on eight CPU nodes.
Amazon EC2 (North Virginia) instance prices: c5.24xlarge (Intel DAAL) – $4.08 per hour ($32.64 per hour for eight nodes), p3dn.24xlarge (RAPIDS cuML) – $31.212 per hour.
With the oneAPI programming model9, Intel delivers high performance, not only on the CPU, but also on its coming architectures (discrete GPU, FPGA, and other accelerators). oneAPI is delivering unified and open programming experience to developers on the architecture of their choice without compromising performance. You can try Intel DAAL in the Intel® DevCloud development sandbox10.
Intel DAAL K-means Implementation and Optimization Details
The K-means algorithm is based on computation of distances since it’s used in cluster assignments and objective function (inertia) calculation. The distance in d-dimensional Euclidean space between an observation s = (s1, s2, …, sd) and a centroid c = (c1, c2, …, cd) is described by the following expression:
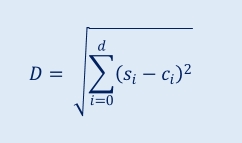
This is equal mathematically to:

Thus, the squared distance is:

To calculate squared distances, the K-means implementation in Intel DAAL splits observations into blocks of fixed size and then processes them in parallel using Intel® Threading Building Blocks.
Component ![]() can be presented as an element mjn of matrix M = 2 S × C, where j is an index of an observation in a block, n is an index of a centroid, and S and C are matrices of a block of observations and centroids, respectively. To calculate this matrix of distance components, Intel DAAL uses matrix multiplication from Intel® oneAPI Math Kernel Library (oneMKL).
can be presented as an element mjn of matrix M = 2 S × C, where j is an index of an observation in a block, n is an index of a centroid, and S and C are matrices of a block of observations and centroids, respectively. To calculate this matrix of distance components, Intel DAAL uses matrix multiplication from Intel® oneAPI Math Kernel Library (oneMKL).
The first squared distance component, ![]() is constant and can be calculated only once for each observation, while two others (
is constant and can be calculated only once for each observation, while two others ( ![]() and
and ![]() ) is recalculated at each iteration.
) is recalculated at each iteration.
At all K-means computation stages, Intel DAAL uses vector instructions from Intel® Advanced Vector Extensions 512 in the 2nd generation Intel Xeon Scalable processors when computing matrix multiplication, centroid assignments, and centroid recalculation.
Using advanced software optimization techniques and enabling hardware features allows Intel DAAL to deliver high performance K-means clustering.
Install scikit-learn from the Intel Distribution for Python and daal4py
The best way to install scikit-learn from the Intel Distribution for Python or daal4py (the Python interface for Intel DAAL)11 is by creating a new conda* environment.

Code Examples
The following example shows dataset generation with scikit-learn:

The following example shows how to run K-means with scikit-learn from Intel Distribution for Python:

The following example shows how to run K-means with daal4py:

K-means Training Configuration
- CPU configuration: c5.24xlarge Amazon EC2 instances; 2nd generation Intel Xeon Scalable processors, two sockets, 24 cores per socket, Intel® Hyper-Threading Technology on, Turbo on, 192 GB RAM (12 slots, 16 GB, 2933 MHz), BIOS: 1.0 Amazon EC2 (ucode: 0x500002c), Operating System: Ubuntu* 18.04.2 LTS.
- GPU configuration: p3dn.24xlarge Amazon EC2 instance; Intel® Xeon® Platinum 8175M processor, two sockets, 24 cores per socket, Intel Hyper-Threading Technology on, Turbo on, 768 GB RAM, 8 NVIDIA Tesla V100-SXM2-32G GPUs with 32 GB GPU memory each, BIOS 1.0 Amazon EC2 (ucode: 0x2000065), Operating System: Ubuntu 18.04.2 LTS.
- Software: Python 3.6, NumPy 1.16.4, scikit-learn 0.21.3, daal4py 2019.5, Intel DAAL 2019.5, Intel® MPI Library 2019.5, RAPIDS cuML 0.10, RAPIDS cuDF 0.10, CUDA* 10.1, NVIDIA GPU driver 418.87.01, Dask 2.6.0.
- Algorithm parameters: Single-precision (float32), number of iterations = 50, threshold = 0, random initial centroids.
References
- Intel®-optimized Frameworks
- Intel®-optimized Libraries
- scikit-learn
- Intel DAAL on GitHub
- K-means++
- RAPIDS 0.9 - A Model Built to Scale: cuML
- Amazon Web Services Elastic Compute Cloud
- Intel® Optane Technology
- Fact Sheet: oneAPI
- Intel® DevCloud
- daal4py: A Convenient Python API to Intel DAAL
- Intel hardware stack for AI
- AWS EC2 Pricing as of 12/02/2019
______
You May Also Like
Machine Learning 101 with Python and daal4py
Watch
Intel® Distribution for Python*
Develop fast, performant Python* code with this set of essential computational packages including NumPy, SciPy, scikit-learn*, and more.
Get It Now
See All Tools