Get the Latest on All Things CODE
Sign Up
By 2024, International Data Corporation (IDC) industry analysts believe the global machine-learning market will grow to a total of $30.6 billion, attaining a compound annual growth rate (CAGR) of 43 percent.1 In that same year, analysts also predict that 143 zettabytes of data will be created, captured, copied, and consumed throughout the world.1
The hardware environments to manage this data across the end-to-end AI workflow are getting more diverse, with unique accelerators coming to market to manage specific use cases. A recent Evans Data Corporation report notes that 40 percent of developers target heterogeneous systems that use more than one type of processor, processor core, or coprocessor.2
For AI, machine learning, and deep-learning developers, it’s an intriguing business opportunity that challenges them to build high-performance applications with flexible deployment options. One hardware architecture can no longer do it all.
To capture this opportunity, achieving peak performance with Python* across a variety of architectures is critical. Python is a powerful, scalable, and easy-to-use language. But it’s not built from the ground up for blazing-fast performance. Many developers rely on vendor-specific optimizations for frameworks and libraries such as TensorFlow*, PyTorch*, or scikit-learn* to achieve the speeds they need on their hardware of choice. Yet, they are left wondering how they can get similar results when new hardware emerges or the market evolves to require deployment on additional hardware types.
That’s where the Intel® oneAPI AI Analytics Toolkit (AI Kit) comes in.
It’s a domain-specific toolkit that’s built on Intel oneAPI cross-architecture performance libraries to accelerate end-to-end data science and AI workflows in the Python ecosystem. The toolkit maximizes performance from preprocessing to machine learning and deep learning training and inference on Intel® hardware architectures—both those commonly used today and those that will become industry standards in the future. The goal is to minimize development costs by providing drop-in acceleration for familiar Python frameworks. Doing so, we empower data scientists and developers to create confidently without being constrained to proprietary program environments or adopting new software APIs every time they need to support a new hardware platform.
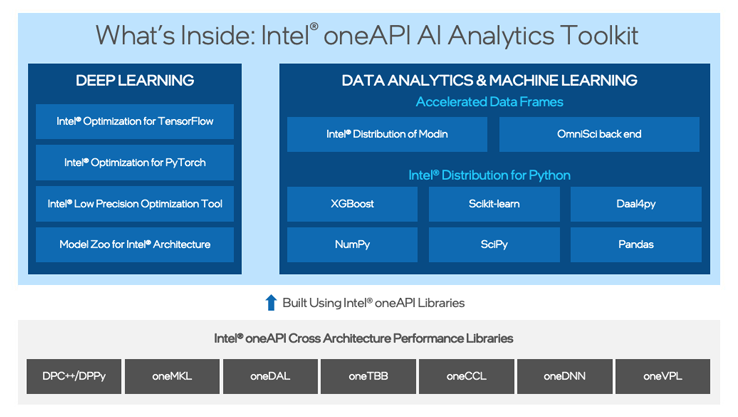
Figure 1. Achieve drop-in acceleration with the AI Kit.
With the AI Kit, you can continue to use your favorite framework or Python library as you transition to Intel® architectures. You’ll get drop-in acceleration with minimal code changes—or even no changes at all.
To demonstrate how this toolkit can help you shatter benchmarks and accelerate workflows on CPUs with little to no added effort, we’ve compiled five benchmarks that span many of today’s most popular libraries.

Let’s look at examples from across the entire AI pipeline: data preprocessing, model training, and model inference.
End-to-End Performance on Census Dataset
The industry-standard census dataset benchmark shows outstanding results when performed with the AI toolkit on CPU architectures. To create these results, we trained a model using 50 years of census data from IPUMS.org to predict income based on education.
Our toolkit enables the model to run much faster when compared to stock libraries. In the benchmark below, there is considerable acceleration across the data science pipeline, boosting ETL by 38x, as well as machine-learning predict and fit with ridge regression by 21x.

To make these results possible, the Intel® Distribution of Modin was employed for data ingestion and ETL alongside the Intel® Extension for Scikit-learn for model training and prediction. Additional performance boosts included 6x improved CSV-read performance as well as 4x improved train test split.
Machine Learning Performance with Intel® Extension for Scikit-learn*
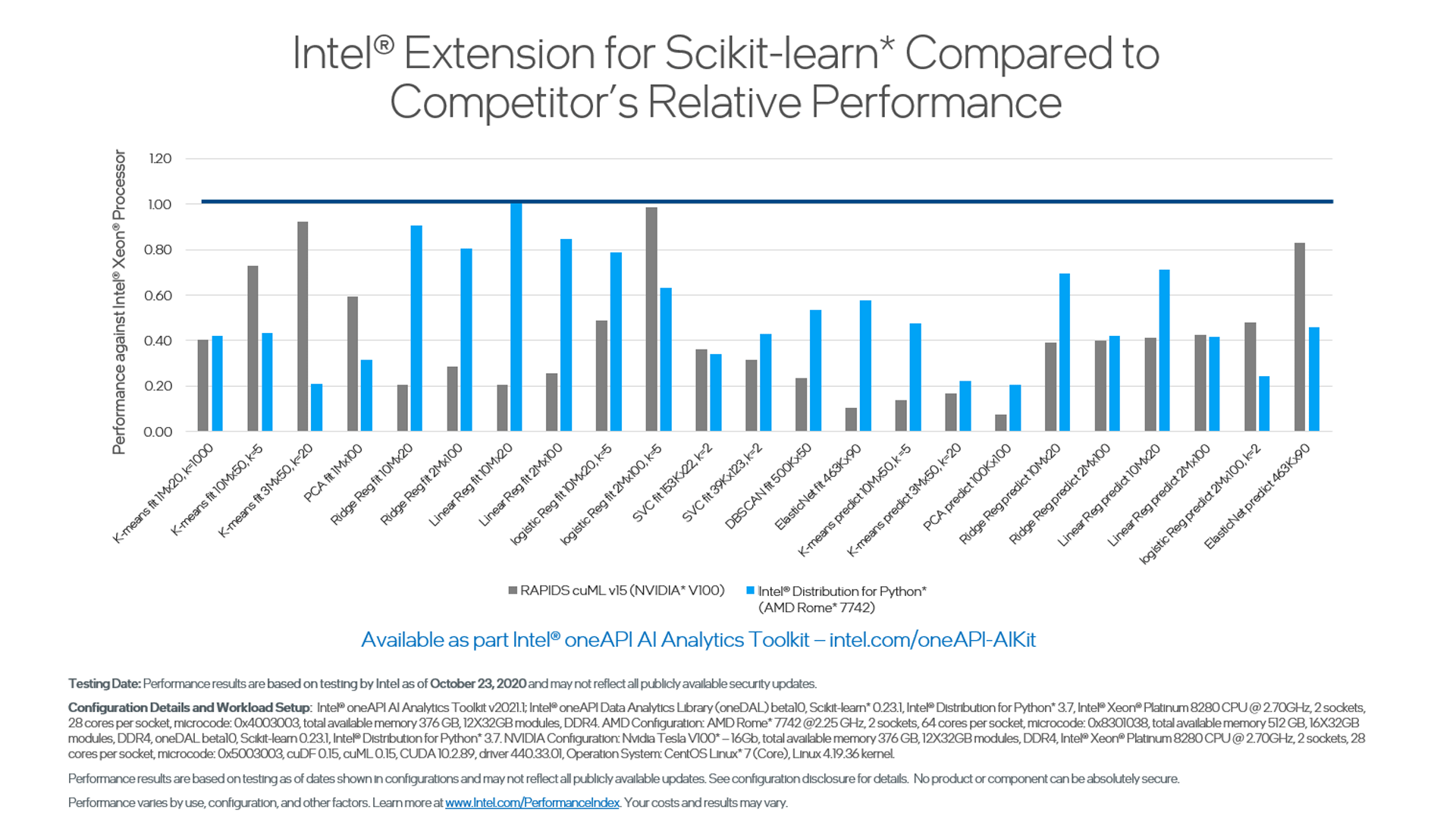
Intel Extension for Scikit-learn helps you achieve highly efficient data layout, blocking, multithreading, and vectorization. In this benchmark, there was a 220x performance boost for the scikit-learn algorithm compared to the stock version.

The Intel Extension for Scikit-learn algorithms also outperform the same algorithms run on the AMD EPYC* 7742 processor. The Intel® Advanced Vector Extensions 512, unavailable on AMD processors, provide much of the performance improvement. We also see that the Intel Extensions for Scikit-learn consistently outperformed the NVIDIA* V100 GPU.
Learn More about Intel Extension for Scikit-learn
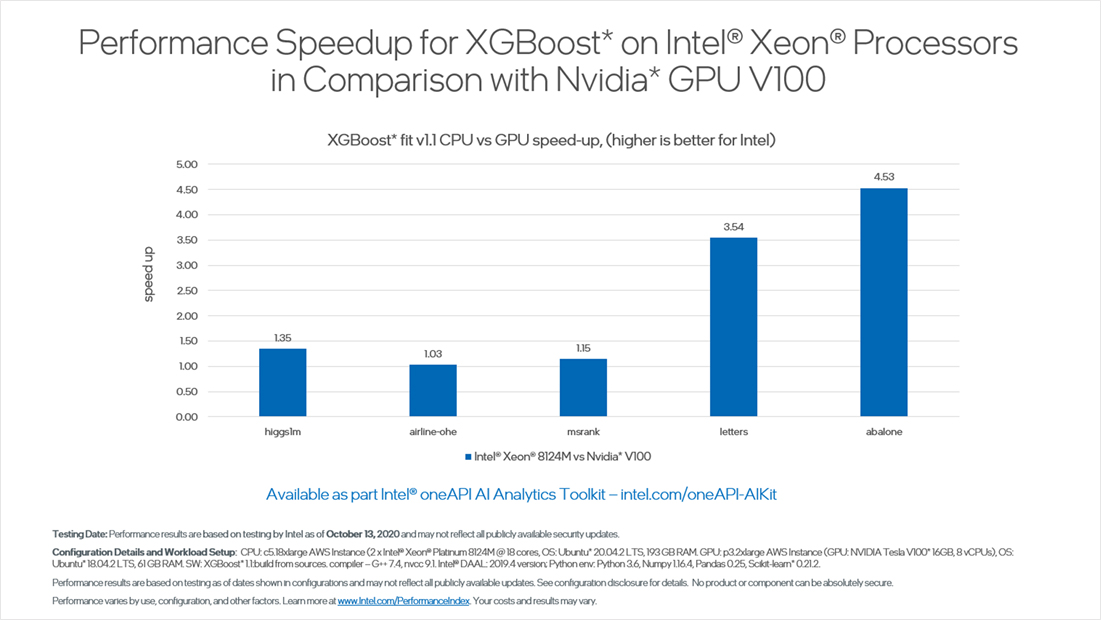
Exceed NVIDIA* GPU Machine Learning Performance with Intel®-optimized XGBoost
Intel actively contributes optimizations to the XGBoost open-source project. XGBoost is an open-source library that provides a gradient-boosting framework for Python and other programming languages. Using the Intel®-optimized XGBoost library for Python offered in our toolkit, you gain up to 4.5x faster inference on Intel® Xeon® processors compared to NVIDIA V100 GPUs. This chart shows how Intel® CPUs provide superior performance for the complex gradient-boosting algorithms commonly used for classification and regression—and how Intel can help remove the cost and effort of offloading such workloads to specialized accelerators.
INT8 Quantized Inference Performance with Minimal Accuracy Loss
There's increasing use of low-precision quantization to boost performance for deep-learning inference workloads. Unfortunately, the speed comes at the cost of reduced accuracy. With the Intel® Low Precision Optimization Tool (Intel® LPOT)—provided as part of the AI Kit—the authors demonstrate inference throughput scaling up to 2.8x with negligible accuracy drop. It’s made possible by the automatic accuracy-driven tuning strategies introduced in the tool.
In the following benchmark, conversion from FP32 to int8 was done using Intel LPOT, and inference was run using Intel® Optimization for TensorFlow*. Both support the Intel® Deep Learning Boost (Intel® DL Boost) technology for faster performance.

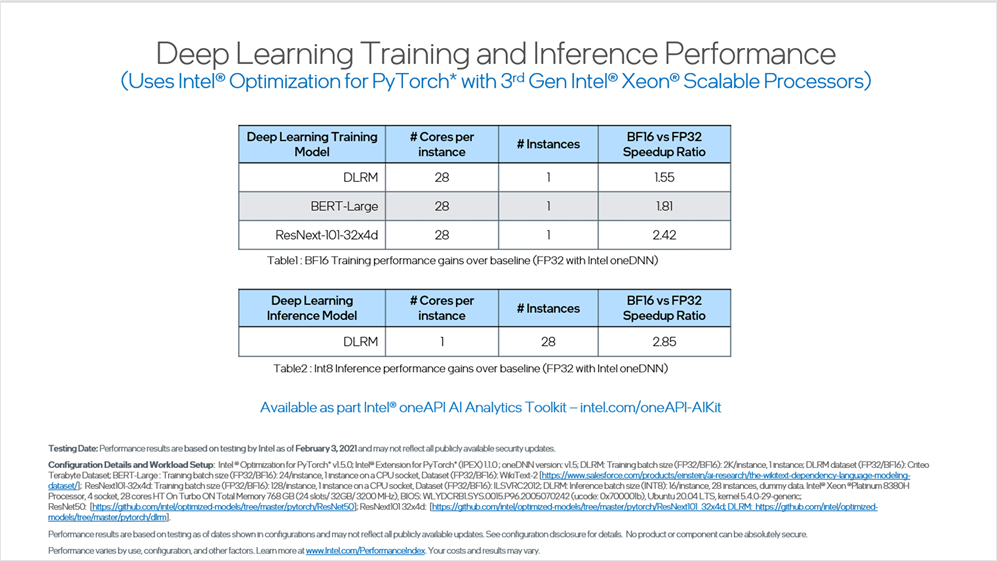
Deep Learning Training and Inference Performance Using Intel® Optimization for PyTorch* with 3rd Generation Intel® Xeon® Scalable Processors
The AI Kit also enhances PyTorch performance on CPU architectures with an Intel-optimized library.
Intel closely collaborates with Facebook* to contribute optimizations to the PyTorch open-source project. Intel also offers a PyTorch extension library to further boost performance for training and inference through automatic type and layout conversions.
Our optimizations leverage Intel DL Boost and BFloat16 technologies to improve training performance of the deep learning recommendation model (DLRM) by up to 1.55x. Meanwhile, Intel DL Boost and int8 optimizations improve the DLRM model inference performance by up to 2.85x when compared to FP32 performance. This benchmark clearly demonstrates superior performance for new age-recommender models as well as computer-vision workloads—enabled by our hardware advancements and software optimizations.
Get Started with the AI Kit
To summarize, the AI Kit provides optimized Python libraries, deep learning frameworks, and a lightweight parallel dataframe—all built using oneAPI libraries—to maximize performance for end-to-end data science and AI workflows on Intel hardware. The toolkit allows data scientists and AI developers to get the latest deep-learning and machine-learning optimizations from Intel from a single resource with seamless interoperability and out-of-the-box performance.
The toolkit is a free download that you can access today. Unlock better cross-architecture Python performance for your AI applications today.
Additional AI Kit Resources
References
- Worldwide Global DataSphere Forecast, 2020–2024: The COVID-19 Data Bump and the Future of Data Growth
- Evans Data Global Development Survey 2020, Volume 2.
______
You May Also Like