Migrate a Stencil Computation Based on CUDA* to DPC++
Clícia Pinto, technical leader and performance engineer. and Lucas Batista, Pedro de Santana, and Georgina González, high-performance computing (HPC) developers, Supercomputing Center SENAI CIMATEC
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Reverse Time Migration (RTM) takes advantage of the finite-difference (FD) method to compute numerical approximations for the acoustic wave equation. It is a computational bottleneck for RTM applications, and therefore needs to be optimized to guarantee timely results and efficiency when allocating resources for hydrocarbon exploration. This article describes our experience migrating an RTM code that's based on CUDA* to Data Parallel C++ (DPC++) using the Intel® DPC++ Compatibility Tool.
RTM Overview and Input Data
In several seismic imaging methods, a stencil is applied in the FD scheme as a numerical solution for the wave equation. This is the case for RTM, widely used in the oil and gas industry to generate images of subsurface structures. Despite the advantages inherent in the method, two major computational bottlenecks characterize it: the high number of floating-point operations during the propagation step and the difficulty in storing the wave fields in main memory. To mitigate the effect of these bottlenecks, engineers seek to explore both the intrinsic parallelism of tasks and the optimization of computational resources, designing solutions capable of running on different accelerators. The optimization of this method represents a great economic advantage for exploration geophysics because it reduces the chances of errors in well drilling. As proposed by Claerbout,1 the RTM algorithm usually has a forward time propagation, a backward propagation, and a cross-correlation of image condition. The flowchart for the RTM algorithm highlights these steps along with host and device communication (Figure 1).
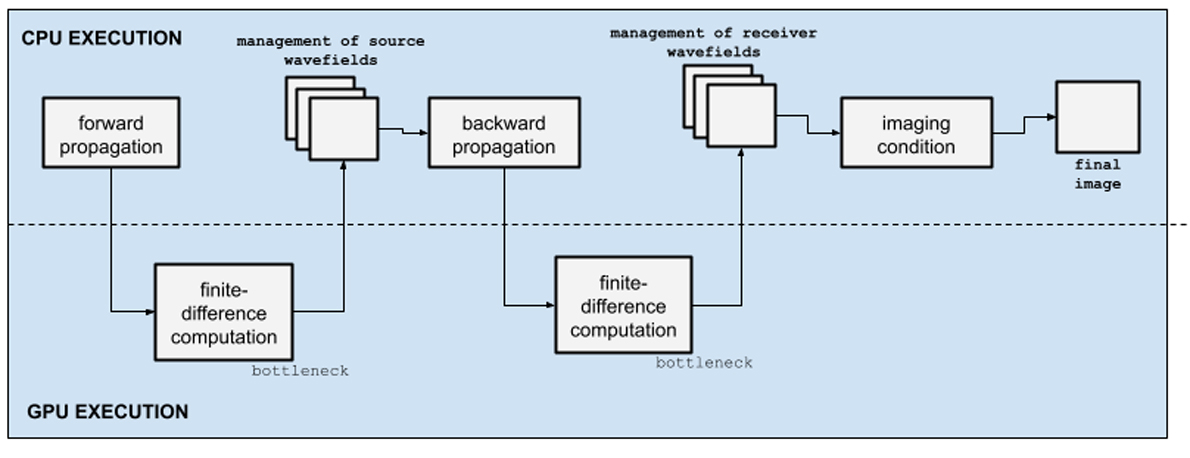
Figure 1. Simplified 2D RTM flowchart
Figure 2 shows the stencil computation in a 2D implementation that's based on CUDA where order is the order of the FD scheme, nx and nz are the size of the input matrix that represents a 2D acoustic velocity model, p is the source/receiver wave field, cx and cy are the x- and y-axes of the FD coefficients, respectively, and l is the extrapolated wave field. In the entire RTM algorithm, the vector P stores the state of pressure points in different time steps. Because of its compute- and data-intensive characteristics, RTM is a suitable candidate for acceleration by specialized processing units.

Figure 2. RTM Stencil Computation Algorithm
Migrate a Reference RTM to oneAPI
The Intel DPC++ Compatibility Tool helps port CUDA language kernels and library API calls to DPC++. Typically, 80%–90% of CUDA source code is automatically migrated, so we structured this process in three steps: preparation, migration, and review. The preparation step seeks to adapt the source code to the migration tool. At this stage, it is necessary to make sure that all CUDA header files are accessible in the default location or in a custom location by using the –cuda-include-path=<path/to/cuda/include> option. In the migration step, the Intel DPC++ Compatibility Tool takes the original application as input and generates annotated DPC++ code. During the review step, we inspect the automatic code conversions, review the annotations to help manually convert unmigrated code, and look for possibilities for code improvement.
During the first migration experience, the Intel DPC++ Compatibility Tool migrated CUDA memory-copy API calls to sycl::queue.memcpy() as shown in Figure 3. Despite having obtained a functional and error-free migrated source code, explicit memory management may not provide the best performance. To investigate memory management improvements, we manually changed the migrated source code to use SYCL buffers and accessors for each data object.

Figure 3. Migrated memory management

Figure 4. DPC++ forward propagation (simplified)
Figure 4 shows DPC++ migrated function that performs the forward time propagation, where nt is the number of time steps needed to model the wave equation. This algorithm shows data objects defined as buffers that are used to control and modify the device’s memory. The backward propagation follows the same structure. Both forward and backward functions perform kernel invocations to handle GPU execution.

Figure 5. DPC++ kernel_lap function invocation
Figure 5 shows DPC++ kernel invocation using the kernel_lap call because that is the main procedure related to stencil computation. Each kernel from our migrated application is submitted to queues targeting a specific device, where data access requirements must be completed before a parallel kernel is launched.
The final RTM image was used to compare the original CUDA implementation to the migrated DPC++ code. To generate the seismic image, we used the input parameters shown in Table 1 and the velocity model shown in Figure 6. The respective output images from the CUDA and DPC++ implementations are shown in Figure 7. The final image from the DPC++ implementation achieved satisfactory accuracy compared to the reference.
Table 1. Parameter description for the specific modeling presented
| Parameters | Values |
|---|---|
| points in z axis | 195 |
| points in x axis | 375 |
| time steps | 1700 |
| sample intervals in z | 10 |
| sample intervals in x | 10 |
| time step sample intervals | 0.001 |
| frequency peek | 20.0 |
| number of shots | 6 |
| order | 8 |
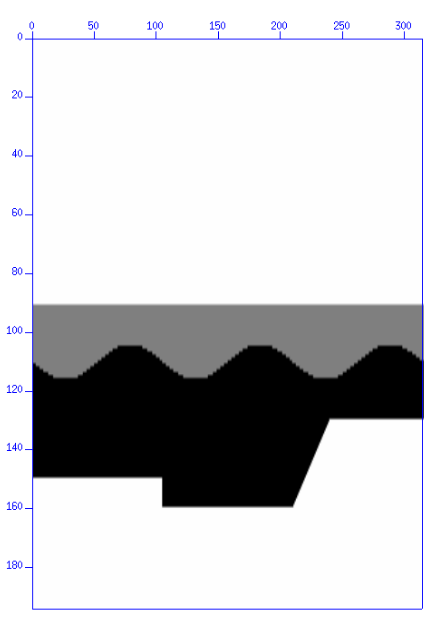
Figure 6. Koslov velocity model

Figure 7. Seismic image generated by the original CUDA-based RTM source code (left) and the migrated DPC++ code (right)
Memory Management Improvements
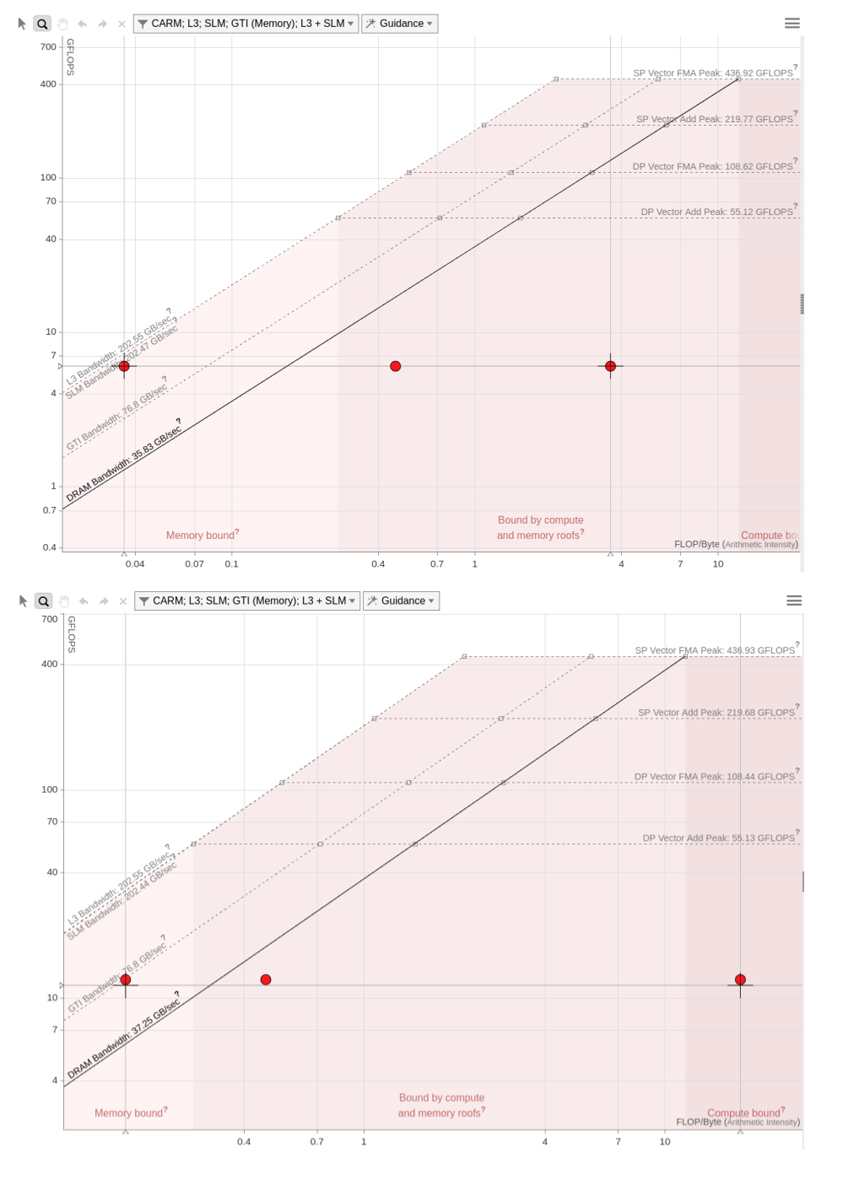
Figure 8. Roofline views of the DPC++ version running on NEO with 9th generation Intel® HD Graphics using explicit memory allocation (top) and buffers/accessors memory management (bottom)
To explore DPC++ memory management options, we developed a buffer/accessor-based version from our migrated application. This strategy eliminates the need to explicitly allocate and free memory on the device. It also eliminates the need to manage data transfer to/from different processing units. To achieve this, we created buffers/accessors for each structure that were explicitly copied to the device. The buffers are destroyed after the computation is completed, and data are copied back to the host (memory synchronization). Braces create a scope around the buffer definition where data objects can be shared. When execution leaves this scope, there is a synchronization between execution flows and the buffers are destroyed. For comparison between original and modified migrated source code, we performed a roofline analysis using Intel® Advisor to estimate the performance. This was done by evaluating the hardware limitations and data transactions between the different memory layers on the system.
Figure 8 shows the roofline graph for a simplified RTM execution with only a single time step. Since we have a reduced number of floating-point operations, we can expect low-performance metrics. The top graph shows the roofline for the migrated source code that uses explicit data management. It achieved a performance of 6.052 gigaFLOPS, with an arithmetic intensity of 3.617 FLOP/byte. Arithmetic intensity can be understood as the ratio of total floating-point operations to the amount of data being moved (memory traffic). The bottom graph shows the roofline for the buffer/accessor version, which achieved twice the performance: 12.246 gigaFLOPS with an arithmetic intensity of 17.896 FLOP/byte.
Conclusion
This paper describes a successful oneAPI proof-of-concept to migrate an RTM code from CUDA to DPC++ using the Intel DPC++ Compatibility Tool, and then tune it using Intel Advisor. The migrated source code is more readable and easier to maintain because it unifies the algorithm execution flow for our application in a unique structure. Besides migration experience, we could easily explore memory management by applying buffers/accessors to achieve better performance and arithmetic intensity. The source code described in this article is available in a public repository along with instructions.2
References
- Claerbout, JF. Toward a unified theory of reflector mapping. Geophysics, v. 36, n. 3, p. 467-481, 1971.
- Finite Difference Computation (GitHub*)
______
You May Also Like
Get the Software
Intel® oneAPI Base Toolkit
Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures.
Get It Now