Gather Data Sampling (GDS) is a transient execution side channel vulnerability affecting certain Intel processors. In some situations when a gather instruction performs certain loads from memory, it may be possible for a malicious attacker to use this type of instruction to infer stale data from previously used vector registers1. These entries may correspond to registers previously used by the same thread, or by the sibling thread2 on the same processor core.
Similar to data sampling transient execution attacks like Microarchitectural Data Sampling (MDS), GDS may allow a malicious actor who can locally execute code on a system to infer the values of secret data which is otherwise protected by architectural mechanisms. GDS differs from the MDS vulnerabilities in both the method of exposure (which is limited to the set of gather instructions), and in the data exposed (stale vector register data only). Neither MDS nor GDS, by themselves, provide malicious actors the ability to choose which data is inferred using these methods.
GDS is assigned CVE-2022-40982 with a CVSS Base Score of 6.5 Medium CVSS:3.1/AV:L/AC:L/PR:L/UI:N/S:C/C:H/I:N/A:N.
Intel is providing a microcode update to mitigate GDS. No software changes are required to enable the mitigation. If there is a performance impact in a specific workload due to the mitigation, it may be possible to disable the mitigation using software controls (see examples in the Software and Deployment Guidance section or your software vendor’s release information for details). Additional information can be found in the Performance Considerations section.
The microarchitectural details in this document are applicable to processors that are affected by GDS and should not be considered universal to all processors. Refer to the Affected Processors section for details.
System administrators, application developers, and users should carefully consider the threat model applicable to their systems when deciding whether and where to mitigate GDS. Based on the environmental threat model, users may disable the GDS mitigation with options provided by operating system vendors (OSVs). Intel is not aware of any instance of any of this vulnerability being exploited outside a controlled lab environment.
Impact Summary
Malicious software may be able to infer data previously stored in vector registers1 used by either the same thread, or the sibling thread on the same physical core. These registers may have been used by other security domains such as other virtual machine (VM) guests, the operating system (OS) kernel, or Intel® Software Guard Extensions (Intel® SGX) enclaves. Note that no processors that support Intel® Trust Domain Extension (Intel® TDX) are affected by GDS.
Background and Issue Description
Gather is a feature provided by Intel® Advanced Vector Extensions 2 (Intel® AVX2) and Intel® Advanced Vector Extensions 512 (Intel® AVX-512) . It comprises a collection of single-instruction, multiple data (SIMD) instructions which fetch non-contiguous data elements from memory using vector-index memory addressing.
When a gather instruction performs loads from memory, different data elements are merged into the destination vector register according to the mask specified. In some situations, due to hardware optimizations specific to gather instructions, stale data from previous usage of architectural or internal vector registers may get transiently forwarded to dependent instructions without being updated by the gather loads. These dependent instructions may allow a malicious attacker to infer stale vector register data that is transmitted through a covert channel, such as shared CPU cache.
The scope of stale data exposure through this behavior is limited to the same physical processor core. An attacker with local code execution ability may observe stale data from the same physical processor core on a sampling basis (in this sense, GDS is similar to MDS) but cannot directly control or specify what data can be inferred.
Inferring stale data using a GDS attack requires malicious code to use gather instructions. However, GDS attacks can affect software which does not use gather instructions. Such attacks can expose data processed by instructions that use architectural vector registers explicitly (for example, SIMD or scalar SSE and Intel AVX instructions) as well as those that use internal vector registers implicitly (for example, REP MOVS instructions).
Mitigation Options
Intel is releasing a microcode update which blocks transient results of gather instructions to prevent attacker code from observing speculative results of gather loads. Mitigation is enabled when the patch is loaded, and cross-thread exposure is mitigated even with hyperthreading enabled.
When the mitigation is enabled, there is additional latency before results of the gather load can be consumed. Although the performance impact to most workloads is minimal, specific workloads may show performance impacts of up to 50%. Depending on their threat model, customers can decide to opt-out of the mitigation.
Microcode Mitigation
Mitigation is enabled by default at the time of microcode update. The microcode update provides an MSR interface that allows software to opt-out of the mitigation.
When updated microcode is loaded, the new GDS_CTRL bit of the IA32_ARCH_CAPABILITIES MSR will be set to 1. This indicates support for the GDS_MITG_DIS (bit 4) and GDS_MITG_LOCK (bit 5) bits of the IA32_MCU_OPT_CTRL MSR. These bits allow software to determine the current state of the mitigation and may allow the mitigation to be disabled (if not locked, and if GDS_MITG_DIS is set on all threads for a given core).
See the MSR Control and Enumeration section for details of these controls.
Intel® Software Guard Extensions (Intel® SGX)
On processors affected by GDS, if Intel SGX is enabled and hyperthreading is disabled, loading the updated microcode will mitigate any potential direct attacks using GDS against Intel SGX enclaves.
There will be an Intel SGX TCB Recovery for those Intel SGX-capable affected processors. This TCB Recovery will only attest as up-to-date when the patch has been FIT-loaded (for example, with an updated BIOS), Intel SGX has been enabled by BIOS, and hyperthreading is disabled. In this configuration, the mitigation will be locked to the enabled state. If Intel SGX is not enabled or if hyperthreading is enabled, the mitigation will not be locked, and system software can choose to enable or disable the GDS mitigation.
Intel Key Locker
It may be possible for GDS to infer key values behind Key Locker handles. The only affected processors which support Key Locker are 11th Generation Intel® Core™ processors based on the Tiger Lake microarchitecture. For Tiger Lake systems, Intel recommends that system software does not enable Key Locker (by setting CR4.KL) unless the GDS mitigation is enabled (IA32_MCU_OPT_CTRL [GDS_MITG_DIS] (bit 4) is 0) and locked (IA32_MCU_OPT_CTRL [GDS_MITG_LOCK](bit 5) is 1). This will prevent an adversary that takes control of the system from turning off the mitigation in order to infer the keys behind Key Locker handles.
To support GDS mitigation locking for Key Locker, microcode updates for Tiger Lake systems enable the following model-specific behavior for GDS_MITG_LOCK. On these systems, a write to IA32_MCU_OPT_CTRL MSR with GDS_MITG_DIS (bit 4) value 0 and GDS_MITG_LOCK (bit 5) value 1 will lock both bits at these values until reset. When not locked, writes to IA32_MCU_OPT_CTRL with any value for these bits other than [5:4] = 10b will not affect the value of GDS_MITG_LOCK. Once locked, subsequent writes to GDS_MITG_DIS and GDS_MITG_LOCK will be ignored.
Intel® Trust Domain Extension (Intel® TDX)
No processors that support Intel TDX are affected by GDS.
Software Sequence
The Vector Register Scrubbing Software Sequence section describes a software sequence for scrubbing stale vector register data which, under certain circumstances, can be used in conjunction with the microcode mitigation.
Software and Deployment Guidance
This section provides guidance to operating system vendors (OSVs), virtual machine managers (VMMs), and system operators to evaluate GDS mitigation performance, threat analysis, how system software can manage the enumeration and controls, and ways to opt-out of the mitigation if doing so is within the potential exposure threshold and threat model of your system.
Threat Analysis
Users should consider their use and threat model, trust and assets level in addition to performance consideration when deciding on opting-out of mitigation. Refer to the additional guidance in the Threat Analysis Guidance for Gather Data Sampling documentation.
Performance Considerations
While the performance impact to most workloads is minimal, specific workloads may show high performance impact when GDS mitigation is enabled. Although compilers may generate gather instructions in many applications, many workloads either do not use the relevant gather instructions, or else do not include those instructions as part of the hot path (frequently executed code), and therefore the mitigation will not result in observable performance impact. The workloads most likely to observe performance impact are certain high-performance computing or graphics workloads that heavily use gather instructions in the hot path. Refer to the Compiler Optimization section for more information.
Traditionally, applications that rely on gather instructions for optimized performance tend to show very high CPU utilization, present characteristics that make vectorization possible, and are carefully tuned and optimized to take advantage of these vector extensions. These are normally certain types of scientific, graphics, and engineering applications. Software developers must carefully structure the code so that either the compiler is able to generate those gather instructions or developers themselves can include these instructions through intrinsics or with inline assembly code. Even in software that is not designed or optimized to generate gather instructions, the compiler might be able to generate gather instructions, and thus it might be possible to find these instructions in more general applications.
End users who understand the workload and usage of their computers can decide if any of the CPU-intensive and vectorization-heavy applications are impacted by the microcode update. User tools like perfmon can help users discover the source of the performance impact. Users may disable the GDS mitigation with options provided by OSVs when available; refer to your OS configuration documentation for details, or to this guide to Reading and Writing MSRs in Linux* for information about how to enable and disable MSRs in a debugging environment.
Software Changes
It is possible to alleviate the majority of the performance impact of the GDS mitigation on affected workloads by recompiling the software with a compiler configuration tuned to avoid gather instructions. Refer to the Compiler Optimization section for details. When software performance is not impacted by the GDS mitigation, or when software only runs on systems where the GDS mitigation is disabled, the software does not need to be recompiled.
If GDS mitigation may be disabled in an untrusted guest VM, the software sequence may be considered for the VM-to-VM transition case to scrub the stale vector register data. Refer to the Software Mitigation Sequence section for more information.
Performance Considerations for clwb Instruction
On this specific subset of affected processors, the microcode update supporting GDS mitigation also impacts the latency of the clwb instruction:
| Processor | Stepping | Code Name / Microarchitecture |
|---|---|---|
| 06_55H | 3 | Skylake Server |
| 06_55H | 4 | Skylake Server Skylake D, Bakerville Skylake W Skylake X |
| 06_55H | 6 | Cascade Lake Server |
| 06_55H | 7 | Cascade Lake Server Cascade Lake W Cascade Lake X |
| 06_55H | A, B | Cooper Lake |
The clwb (Cache Line Write Back) instruction can be used to ensure memory is updated with modified data for a cache line, if present, in the cache hierarchy. Unlike the similar clflushopt instruction, the clwb semantics allows an implementation to optionally retain a copy of the cache line in non-modified state. On the processors in Table 1, however, both clwb and clflushopt always fully invalidate the cache line.
On Intel processors for which the GDS mitigation includes changes to the clwb instruction, users may observe performance impact in applications with heavy use of clwb. Such applications are expected to be specific use-cases of non-volatile memory, like certain persistent-memory-enabled databases and some heavy I/O applications and libraries operating on top of non-volatile memory. If impacted, such applications might replace instances of clwb with the clflushopt instruction. On this subset of processors, the clwb and clflushopt instructions have equivalent behavior, but clflushopt latency is unaffected by the microcode update.
On processors code named Cascade Lake or Cooper Lake, the impact to the clwb instruction latency is eliminated when the GDS mitigation is disabled by setting GDS_MITG_DIS.
OS Controls
GDS mitigation is enabled by default when the microcode patch is loaded. It might be possible to use software to enable or disable the mitigation, based on security and performance implications.
Linux*
This section describes the current plans for Linux support for the GDS mitigation; this support will not be present in current kernels, and the details (such as the command line flag and file names) are subject to change.
Intel will work with the open-source ecosystem to add a new Linux kernel command line parameter gather_data_sampling to easily disable the mitigation. The current plan for this parameter, like the existing Linux kernel mitigations, is as indicated in Table 2. Using this boot time parameter is the recommended method to opt-out of this mitigation. Setting kernel boot parameters might differ between Linux distributions. For example, the instructions for Ubuntu* can be found here, while Fedora* instructions are here. Contact your OSV for information about how to modify kernel boot parameters.
| Command Line | Value | Meaning |
| gather_data_sampling | off | Disables mitigation for GDS on affected platforms. |
Setting the parameter “mitigations=off” will also disable the GDS mitigation as stated in the Linux kernel documentation.
The default upstream kernel configuration enables the mitigation by default.
On an up-to-date Linux system, the mitigation status can be read from the file /sys/devices/system/cpu/vulnerabilities/gather_data_sampling
There are other options in which privileged users might be able to manage the mitigation by interacting with the MSRs listed in the MSR Control and Enumeration section. However, those changes might not be persistent. Refer to that enumeration and work with your OSV to identify how to handle those MSRs if a GDS opt-out option is not yet available from your OSV. For example, msr-tools allows handling MSRs in ways that may be an option for privileged users.
Windows*
Intel is working with Microsoft* to provide a mechanism to disable the GDS mitigation in the Windows OS kernel.
Other Operating Systems
Since the GDS mitigation is enabled by default on Intel hardware, software vendors and OSVs provide various configuration options to opt-out of the mitigation for customers whose threat model is low exposure for GDS. See the References section or contact your software vendor provider for documentation about how to opt-out of the mitigation in your particular OS.
Virtualization
Hypervisors (VMMs) should enumerate the GDS controls, both IA32_ARCH_CAPABILITIES[GDS_CTRL | GDS_NO] (bits 25 and 26) and IA32_MCU_OPT_CTRL [GDS_MITG_DIS | GDS_MITG_LOCK] (bits 4 and 5), to the host or root partition so that authorized users can use the controls provided by the root OS to enable and disable the mitigation. Users should be made aware that such controls are global and will affect all VMs on the system.
VM owners may want to know if their VM is affected by GDS. Hypervisors can expose this information to VMs in two ways: via only exposing the GDS_NO bit to guests, or by also exposing the full enumeration in IA32_ARCH_CAPABILITIES and IA32_MCU_OPT_CTRL. VMMs may choose to expose IA32_MCU_OPT_CTRL to guests so that software in the guests can determine if the microcode mitigation is enabled and thus gather instructions may have their performance affected; guest software may then choose alternative implementations that reduce the performance impact. If a VMM chooses to only expose GDS_NO, it should synthesize its value based upon what the processor reports for GDS_NO as well as the state of the mitigation on affected processors running updated microcode.
If the VMM exposes the IA32_MCU_OPT_CTRL interface to guests and does not want the guests to be able to disable the mitigation, it should report the value of GDS_MITG_LOCK as 1. However, a VMM may want to allow guests to disable the mitigation under certain circumstances. One such circumstance would be if the risk considerations allow for it. Another would be if the VMM is able to use the vector register scrubbing software sequence. In the case where the VMM can use the vector register scrubbing software sequence:
- The VMM would enable the microcode mitigation at all times except when the current VM requests that the GDS mitigation to be disabled
- The VMM would disable the microcode mitigation and then execute the software sequence whenever switching into a VM that has requested the GDS mitigation to be disabled.
VMMs which implement mechanisms to prevent VMM-level access to secret data from other guests (known as secret-free VMMs) could allow guests to disable the mitigation without the need to execute the software sequence, until such time as the VMM schedules another untrusted guest on the same physical core (including when a VM is terminated and the cores reassigned), at which time the VMM would need to execute the software sequence.
This scenario assumes the VMM is CPU core scheduling all VMs. The software sequence would not need to be executed when switching into a VM that runs with the mitigation enabled. Note that a VMM running on a processor that does not support the GDS_MITG_DIS or GDS_MITG_LOCK bits can still cause VM exits on MSR accesses to IA32_MCU_OPT_CTRL in order to virtualize them.
VMMs should also consider if they want to enumerate the clwb instruction to some or all guests. This is because not enumerating it would force the guest to instead rely on alternative instructions for cache flushing that are not impacted by the mitigation.
MSR Control and Enumeration
Intel is releasing a microcode update which supports software control of the GDS mitigation. Support for the IA32_MCU_OPT_CTRL MSR and both IA32_MCU_OPT_CTRL[GDS_MITG_DIS] (bit 4) and IA32_MCU_OPT_CTRL[GDS_MITG_LOCK] (bit 5) is enumerated by IA32_ARCH_CAPABILITIES[GDS_CTRL] (bit 25).
When IA32_ARCH_CAPABILITIES[GDS_NO] (bit 26) reports 1, it indicates that this processor is not affected by GDS. Note that not all unaffected processors will be able to enumerate GDS_NO as 1, especially initially. Also note that the attack is not possible where Intel AVX is not supported (as gather instruction support is conditioned on Intel AVX state enabling).
GDS_CTRL may not be enumerated or supported on processors where the attack is not possible.
| Register Address Hex | Register Address Dec | Architectural MSR Name / Bit Fields | MSR / Bit Description | Comment |
|---|---|---|---|---|
| 123H | 291 | IA32_MCU_OPT_CTRL | Microcode Update Option Control (R/W) | If CPUID.(EAX=07H,ECX=0):EDX[9]=1 or IA32_ARCH_CAPABILITIES[25]=1 |
| 123H | 291 | 4 | GDS_MITG_DIS: If 0: GDS mitigation enabled (patch load time default). If 1 on all threads in a core: GDS mitigation is disabled. |
Read/Write Notes: 0/1 Updates (writes) to this MSR change enable/disable the mitigation. GDS_MITG_DIS must be set to 1 on all threads on a core to disable the mitigation. |
| 123H | 291 | 5 | GDS_MITG_LOCK: If 0: Not locked / GDS_MITG_DIS is under OS control. If 1: Locked / GDS_MITG_DIS forced to 0 (writes are ignored). |
Read Only Note: R/W on Tiger Lake. Lock is one-way , and set at MCU load when Intel SGX has been enabled and hyperthreading has been disabled, as configured by BIOS. |
| Register Address Hex | Register Address Dec | Architectural MSR Name / Bit Fields | MSR / Bit Description | Comment |
|---|---|---|---|---|
| 10AH | 266 | IA32_ARCH_CAPABILITIES | Enumeration of Architectural Features (RO) | If CPUID.(EAX-07H, ECX=0):EDX[29]=1 |
| 10AH | 266 | 25 | GDS_CTRL: Enumeration for support of both IA32_MCU_OPT_CTRL[4] and IA32_MCU_OPT_CTRL[5]. | |
| 10AH | 266 | 26 | GDS_NO: The processor is not vulnerable to Gather Data Sampling. |
Affected Processors
Refer to the consolidated affected processor table (2022-2023 tab, Gather Data Sampling column) for a list of currently-supported processors affected by this issue. Processors that are affected should load the latest microcode to enable the GDS mitigation.
Vector Register Scrubbing Software Sequence
This section describes a software sequence which can be used to scrub the contents of unused vector register file entries on certain processors. This may be helpful for software when switching to a security domain that is not trusted by the previous security domain (for example, when a VMM switches between mutually untrusted guests), but where the GDS mitigation will not be enabled during execution of that security domain (such as where the GDS_MITG_DIS MSR will be set to 1).
When hyperthreading is enabled, an SMT-aware version of the sequence needs to be used, as documented below. Similarly, when the untrusted security domain can execute Intel AVX-512 instructions, an Intel AVX-512 version of the sequence needs to be used.
This software sequence is not architecturally guaranteed and is only effective under specific architectural and microarchitectural conditions; in particular, it may not be effective if interrupted or otherwise disrupted by other system activity. Software using this sequence can use execution time to attempt to observe whether such disruptions have occurred.
Software Sequence Overview
The figures below show an overview of the software sequence when SMT is enabled (Figure 1) and when SMT is disabled (Figure 2). When SMT is enabled, thread 0 and thread 1 are the threads of the same physical core: we refer to thread 0 as the “primary thread,” and thread 1 as the “secondary thread.” The “pre-sequence” step ensures that the vector register entries corresponding to the architectural registers have been scrubbed, while the “core flow” step is responsible for scrubbing the unused vector register file entries.

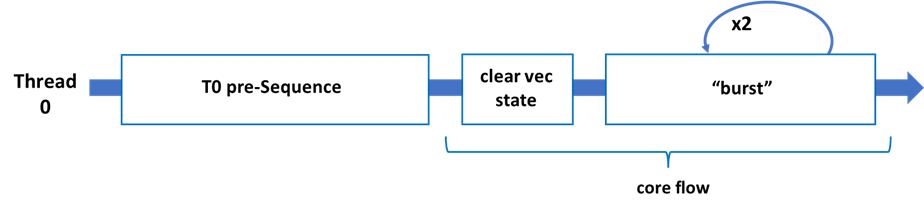
Since the sequence modifies both the x87 and Intel AVX states, both x87 and Intel AVX must be enabled during execution. Additionally, x87 and Intel AVX register contents must be saved and restored after the sequence if necessary.
Prerequisites
The pre-sequence is responsible for scrubbing any data in the vector register file entries corresponding to the architectural registers. This is ensured by writing full-width data (meaning 512-bit where Intel AVX-512 is supported, and 256-bit otherwise) to all vector registers. Software may wish to invoke VERW after the pre-sequence to ensure that other relevant microarchitectural structures are also scrubbed.
Intel recommends the pre-sequence code below:
; ensure SSE/AVX/AVX512 registers are not all zero
vpternlogd zmm31, zmm31, zmm31, 0xff
vpternlogd zmm15, zmm15, zmm15, 0xff
vpternlogd zmm7, zmm7, zmm7, 0xff
; use VERW on processors which need MD_CLEAR
sub rsp, 8
mov WORD PTR [rsp], ds
verw WORD PTR [rsp]
add rsp, 8
; overwrite zmm0 with zero and rewrite
vxorps zmm0, zmm0, zmm0
vxorps zmm0, zmm0, zmm1
; rewrite zmm1-zmm31 by XORing with zero
vxorps zmm1, zmm1, zmm0
vxorps zmm2, zmm2, zmm0
[…]
vxorps zmm30, zmm30, zmm0
vxorps zmm31, zmm31, zmm0
To minimize the impact of factors such as instruction cache misses on the timing of the sequence, the pre-sequence should perform a “warm-up” by executing the core flow on the primary thread.
Sequence Core Flow
The sequence body is the part of the sequence that carries out the scrubbing of the vector registers affected by GDS (the “core flow” that shall not be disturbed), including:
- Vector execution state clearing:
; clear vector execution state fld1 fld1 fpatan fstp st(0) - “Burst” sequence to scrub the unused vector register entries. In this example we use 256 repeats of two Intel AVX-512 instructions:
; burst sequence lfence .rept 256 vxorps zmm2, zmm1, zmm2 vxorps zmm3, zmm1, zmm3 .endr lfence - “Sync and wait loop” for cross-thread synchronization at the beginning and the end of the sequence body:
; wait busyloop .align 64 waitloop: cmp [SMT_DONE], 0 mfence pause lfence je waitloop lfence
Disruption Detection
Software can attempt to observe disruptions by measuring the execution time of the “core flow” part the sequence. When the sequence takes significantly longer to execute than expected, software can assume that the sequence was disrupted, and should then execute the sequence body again. Such disruptions may mean that the sequence fails to clear all vector register file entries. Since the likelihood of vector register file entries remaining unscrubbed is reduced even after disrupted executions, software may wish to consider limiting the maximum number of retries of the sequence to avoid excessive execution time.
To measure execution time, the rdpmc instruction can be used to read the fixed core cycle counter. Intel recommends measuring the entire sequence body (“core flow”), including the cross-thread synchronization.
; timestamp using rdpmc
mov ecx, 0x40000001
rdpmc
lfence
Note that where the Intel AVX-512 version of the sequence is used but software has not recently been using Intel AVX-512 instructions, the software sequence (and other code) may execute slowly for a period of time due to voltage guard-band restrictions.
Although alternative approaches may exist for disruption detection, such as using performance counters and interrupt counters, Intel recommends that software uses the timing-based approach where possible. Where SMT is enabled, software can consider measuring the number of iterations of the “sync and wait loop” as an additional data point for detecting disruption.
Compiler Optimizations
Loading an updated MCU fully mitigates GDS by default. No further action is required. For certain workloads whose performance is impacted by the mitigation, it may be possible to improve performance by rebuilding the binary to reduce the usage of gather instructions. One possible step may be to enable compiler flags that suppress the generation of gather instructions in generated code. Different compilers support different flags for this purpose. Refer to the table below for details.
Note: Some programs or libraries may specify gather instructions directly using compiler intrinsics or assembly. Such usages may be unaffected by these compiler flags.
| Compiler | Flags |
|---|---|
| ICX (Intel® oneAPI DPC++/C++ compiler) | -Xclang -target-feature -Xclang +prefer-no-gather (use 2023.1 version or newer) or -mno-gather option in ICX 2024.0. |
| GCC | -mtune-ctrl=^use_gather,^use_gather_2parts,^use_gather_4parts or -mno-gather option in GCC 13.3 / GCC 12.4 / GCC 11.5 and GCC 14. |
| Clang (LLVM) | -mno-gather option in LLVM18 |
| MSVC (Microsoft* Visual C compiler) | N/A |
| ICC (Intel® C Compiler) | None. Not supported. |
Since this requires recompiling the source code, if the application uses third-party libraries that cannot be recompiled, setting these compiler flags will have no impact if those third-party libraries include gather instructions. Even for the recompiled code, currently the gather intrinsic would continue to generate gather instructions. The application might still benefit from recompiling if most of the gather instructions in the hot path are in the main application rather than in third-party libraries.
Terminology
Stale registers: Stale registers are entries in the register file which hold old values of registers (values that were previously used).
Vector Registers: Storage areas in a CPU core that contain the operands and results for vector computations. Note that these registers may also hold temporary values used by non-vector operations.
References
- Threat Analysis Guidance for Gather Data Sampling
- Reading and Writing Model Specific Registers (MSRs) in Linux*
- Gather Data Sampling Mitigation Performance Analysis
- Gather Data Sampling Advisory Guidance
- Intel microcode repository
- Linux kernel parameters documentation
- Microsoft knowledgebase for Gather Data Sampling
- Ubuntu boot parameters documentation
- Fedora boot parameters documentation
- FreeBSD* configuration documentation
- Debian* configuration documentation
- SUSE* configuration documentation