Introduction
Memcpy is an important and often-used function of the standard C library. Its purpose is to move data in memory from one virtual or physical address to another, consuming CPU cycles to perform the data movement. Intel® I/O Acceleration Technology (Intel® I/OAT) allows offloading of data movement to dedicated hardware within the platform, reclaiming CPU cycles that would otherwise be spent on tasks like memcpy. This article demonstrates describes a usage of Storage Performance Development Kit (SPDK) with the Intel® I/OAT DMA engine, which is implemented through the Intel® QuickData Technology Driver. The SPDK provides an interface to Intel I/OAT hardware directly from user space, which greatly reduces the software overhead involved in using the hardware. Intel I/OAT can take advantage of PCI-Express nontransparent-bridging, which allows movement of memory blocks between two different PCIe connected motherboards, thus effectively allowing the movement of data between two different computers at nearly the same speed as moving data in memory of a single computer. We include a sample application that contrasts performance of memcpy and Intel I/OAT equivalent functionality when moving a series of different sized chunks of data in memory. The benchmarks are logged and results compared. To download the sample application, click on the button at the top of this article.
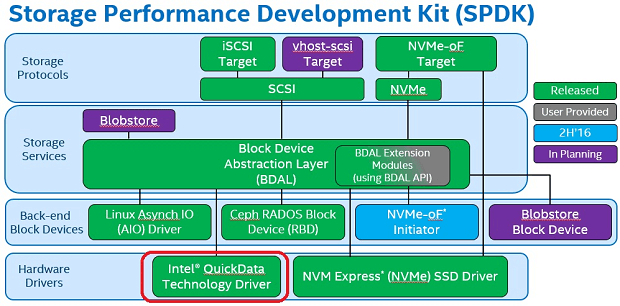
Figure 1: The SPDK is an end-to-end reference architecture for Storage.
Hardware and Software Configuration
See below for information about the hardware and software configuration of the system used to create and validate the technical content of this article and sample application.
| CPU and Chipset | Intel® Xeon® processor E5-2699 v4, 2.2 GHz
|
| Platform | Platform: Intel® Server System R2000WT product family
|
| Memory | Memory size: 256 GB (16X16 GB) DDR4 2133P Brand/model: Micron* – MTA36ASF2G72PZ2GATESIG |
| Storage | Brand and model: 1 TB Western Digital* (WD1002FAEX) Plus Intel® SSD Data Center P3700 Series (SSDPEDMD400G4) |
| Operating System | Ubuntu* 16.04 LTS (Xenial Xerus*) Linux* kernel 4.4.0-21-generic |
Note: SPDK can run on various Intel® processor families with platform support for Intel I/OAT.
Why Use Intel® Storage Performance Development Kit?
Solid-state storage media is becoming a part of the storage infrastructure in the data center. Current-generation flash storage enjoys significant advantages in performance, power consumption, and rack density over rotational media. These advantages will continue to grow as next-generation media enter the marketplace.
The SPDK is all about efficiency and scalable performance. The development kit reduces both processing and development overhead, and ensures the software layer is optimized to take advantage of the performance potential of next-generation storage media, like Non-Volatile Memory Express* (NVMe) devices. The SPDK team has open-sourced the user mode NVMe driver and Intel I/OAT DMA engine to the community under a permissive BSD license. The code is available directly through the SPDK GitHub* page.
Prerequisites-Building the sample application (for Linux):
SPDK runs on Linux with a number of prerequisite libraries installed, which are listed below.
- Install the dependencies:
- a c++14 compliant c++ compiler
- cmake >= 3.1
- git
- make
- CUnit library
- AIO library
- OpenSSL library
>sudo apt-get update >sudo apt-get install gcc g++ make cmake git libcunit1-dev libaio-dev libssl-dev - Get the latest version of the SPDK, using the get_spdk.bash script included with the sample application. The script will download the SPDK from the official GitHub* repository, build it, and then install it in “./spdk”directory.
>bash ./libs/get_spdk.bash - Build from the “ex4” directory:
mkdir <build-dir>cd <build-dir>cmake -DCMAKE_BUILD_TYPE=Release $OLDPWDmake
- Getting the system ready for SPDK:
The following command needs to be run once before running any SPDK application. It should be run as a privileged user.- (
cd ./spdk && sudo scripts/setup.sh)
- (
Getting Started with the Sample Application
The sample application contains the following:
Figure 2: List of files that are parts of the sample application
This example goes through the following steps to show the usage of the Intel I/OAT driver:
Program Setup
- In the “main.cpp” file, the program calls probes the system for Intel I/OAT devices and calls a callback function for each device. If the probe callback returns true, then SPDK will go ahead and attach the Intel I/OAT device and on its success call the attach callback function.
spdk_ioat_chan* init_spdk() { char* args[] = {(char*)("")}; rte_eal_init(1, args); spdk_ioat_chan* chan = nullptr; // Probe available devices. // - 'probe_cb' is called for each device found. // - 'attach_cb' is then called if 'probe_cb' returns true auto ret = spdk_ioat_probe((void*)(&chan), probe_cb, attach_cb); if (ret != 0) return nullptr; return chan; } - Then, the main program defines each test and sets up the buffers.
// Each test is defined by 2 number {a, b}. // We're copying chunks of 2^a bytes inside a 2^b bytes buffer. const std::vector<std::pair<uint8_t, uint8_t>> tests = { {1, 5}, {3, 5}, {3, 9}, {5, 9}, {7, 9}, {7, 13}, {9, 13}, {11, 13}, {11, 17}, {13, 17}, {15, 17}, {15, 21}, {17, 21}, {19, 21}, {19, 25}, {21, 25}, {23, 25}, {23, 29}, {25, 29}, {27, 29}}; - After setting up the buffers, the main runs through three different
memcpyroutines in a for-loop. The first routine is using the regularmemcpyfrom the standard C library.benchmark seq_memcpy(uint64_t chunk_size, uint64_t buffer_size) { using namespace std::chrono_literals; // Allocate the whole buffer, 8 bytes-aligned uint64_t* buffer64 = new uint64_t[buffer_size / sizeof(uint64_t)]; uint8_t* buffer8 = reinterpret_cast<uint8_t*>(buffer64); // Trick the optimizer into not optimizing any copies away utils::escape(buffer8); // Fill the buffer with random data random_number_generator<uint64_t> rnd; for (uint i = 0 / sizeof(uint64_t); i < buffer_size / sizeof(uint64_t); ++i) { buffer64[i] = rnd.get(); } uint64_t iterations = 0; std::chrono::nanoseconds time = 0s; uint64_t nb_chunks = buffer_size / chunk_size; random_number_generator<uint64_t> chunk_idx_gen(0, nb_chunks / 2 - 1); do { // pick a random even-indexed buffer as source uint64_t src_chunk_idx = chunk_idx_gen.get() * 2; // pick a random odd-index buffer as destination uint64_t dst_chunk_idx = chunk_idx_gen.get() * 2 + 1; auto start_cpy = std::chrono::steady_clock::now(); // performs the copy memcpy( buffer8 + (dst_chunk_idx * chunk_size), buffer8 + (src_chunk_idx * chunk_size), chunk_size); time += (std::chrono::steady_clock::now() - start_cpy); // Trick the optimizer into not optimizing any copies away utils::clobber(); ++iterations; } while (time < 1s); delete[] buffer64; return {chunk_size, buffer_size, time, iterations}; } - The second routine uses the Intel I/OAT driver to perform the sequential memory copy using the Intel I/OAT channels.
benchmark seq_spdk(uint64_t chunk_size, uint64_t buffer_size, spdk_ioat_chan* chan) { using namespace std::chrono_literals; // Allocate the whole buffer, 8 bytes-aligned uint64_t* buffer64 = (uint64_t*)spdk_malloc(buffer_size, sizeof(uint64_t), nullptr); uint8_t* buffer8 = reinterpret_cast<uint8_t*>(buffer64); // Trick the optimizer into not optimizing any copies away utils::escape(buffer8); // Fill the buffer with random data random_number_generator<uint64_t> rnd; for (uint i = 0 / sizeof(uint64_t); i < buffer_size / sizeof(uint64_t); ++i) { buffer64[i] = rnd.get(); } uint64_t iterations = 0; std::chrono::nanoseconds time = 0s; uint64_t nb_chunks = buffer_size / chunk_size; random_number_generator<uint64_t> chunk_idx_gen(0, nb_chunks / 2 - 1); bool copy_done = false; do { // pick a random even-indexed buffer as source uint64_t src_chunk_idx = chunk_idx_gen.get() * 2; // pick a random odd-index buffer as destination uint64_t dst_chunk_idx = chunk_idx_gen.get() * 2 + 1; auto start_cpy = std::chrono::steady_clock::now(); copy_done = false; // Submit the copy. req_cb is called when the copy is done, and will set 'copy_done' to true spdk_ioat_submit_copy( chan, ©_done, req_cb, buffer8 + (dst_chunk_idx * chunk_size), buffer8 + (src_chunk_idx * chunk_size), chunk_size); // We wait for 'copy_done' to have been set to true by 'req_cb' do { spdk_ioat_process_events(chan); } while (!copy_done); time += (std::chrono::steady_clock::now() - start_cpy); // Trick the optimizer into not optimizing any copies away utils::clobber(); ++iterations; } while (time < 1s); spdk_free(buffer64); return {chunk_size, buffer_size, time, iterations}; } - The third routine uses the Intel I/OAT driver to perform the parallel memory copy using the Intel I/OAT channels.
benchmark par_spdk(uint64_t chunk_size, uint64_t buffer_size, spdk_ioat_chan* chan) { using namespace std::chrono_literals; // Allocate the whole buffer, 8 bytes-aligned uint64_t* buffer64 = (uint64_t*)spdk_malloc(buffer_size, sizeof(uint64_t), nullptr); uint8_t* buffer8 = reinterpret_cast<uint8_t*>(buffer64); // Trick the optimizer into not optimizing any copies away utils::escape(buffer8); // Fill the buffer with random data random_number_generator<uint64_t> rnd; for (uint i = 0 / sizeof(uint64_t); i < buffer_size / sizeof(uint64_t); ++i) { buffer64[i] = rnd.get(); } uint64_t iterations = 0; std::chrono::nanoseconds time = 0s; uint64_t nb_chunks = buffer_size / chunk_size; std::mt19937 random_engine(std::random_device{}()); do { // We want to match each source chunk with a random destination chunks, // while making sure we're not copying several chunk to the same destination std::vector<int> src_pool(nb_chunks / 2); std::vector<int> dst_pool(nb_chunks / 2); for (int i = 0; i < nb_chunks / 2; ++i) { src_pool.push_back(i); dst_pool.push_back(i); } std::shuffle(src_pool.begin(), src_pool.end(), random_engine); std::shuffle(dst_pool.begin(), dst_pool.end(), random_engine); // For each parallel copy, we need a flag telling us if the copy is done std::vector<int> copy_done(nb_chunks / 2, 0); auto start_cpy = std::chrono::steady_clock::now(); for (int i = 0; i < nb_chunks / 2; ++i) { // Even-indexed chunk used as source uint64_t src_chunk_idx = src_pool[i] * 2; // Odd-indexed chink used as destination uint64_t dst_chunk_idx = dst_pool[i] * 2 + 1; // Submit 1 copy spdk_ioat_submit_copy( chan, ©_done[i], req_cb, buffer8 + (dst_chunk_idx * chunk_size), buffer8 + (src_chunk_idx * chunk_size), chunk_size); } // We wait for all copies to be done do { spdk_ioat_process_events(chan); } while ( std::any_of(copy_done.cbegin(), copy_done.cend(), [](int done) { return done == 0; })); time += (std::chrono::steady_clock::now() - start_cpy); // Trick the optimizer into not optimizing any copies away utils::clobber(); iterations += (nb_chunks / 2); } while (time < 1s); spdk_free(buffer64); return {chunk_size, buffer_size, time, iterations}; } - Once the three routines are complete, the main program displays the results for each for-loop iteration.
- Finally, after completing the for-loop, the main program releases the buffers.
void uninit_spdk(spdk_ioat_chan* chan) { spdk_ioat_detach(chan); }
BIOS Setup
Before running the application, the platform needs to enable the Intel I/OAT feature in the BIOS for each CPU socket; otherwise, the sample program will not run.
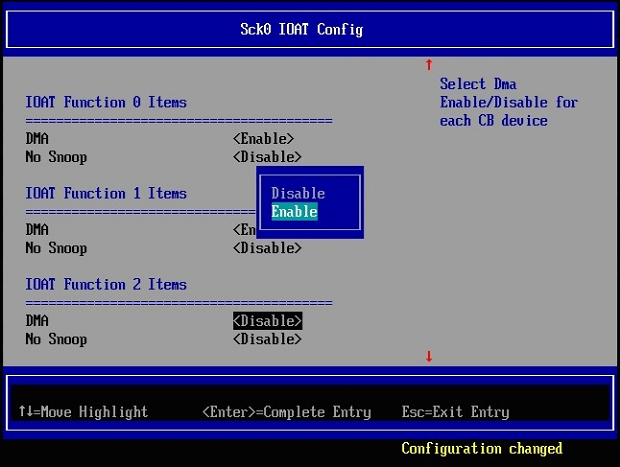
Figure 3: BIOS setting for Intel I/OAT function
SPDK Setup
After the BIOS setup is done, SPDK needs to be initialized for the application to recognize all of the Intel I/OAT channels.
cd /spdk/scripts
sudo ./setup.sh
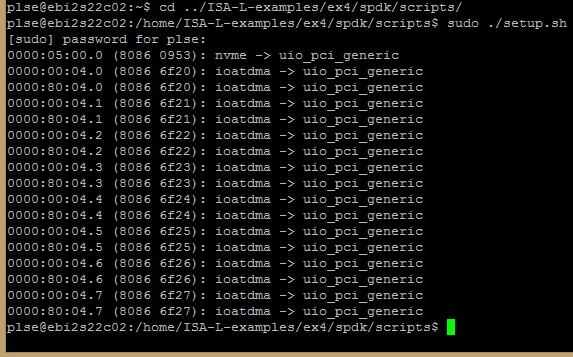
Figure 4: Setting up the Intel I/OAT channels
Run the Example
sudo ./ex4
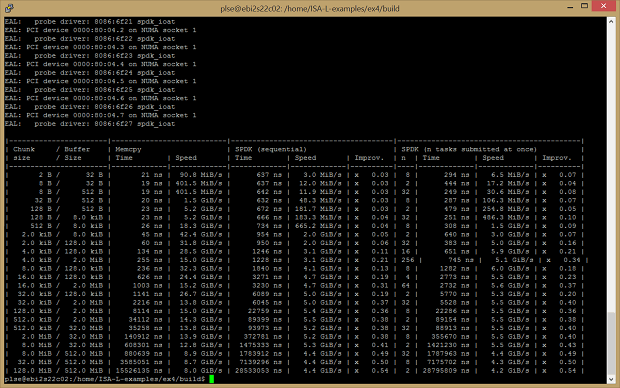
Figure 5: Results of the memcpy and Intel I/OAT equivalent function
From the output, storage developers can use the results as a guide to determine the best combination of chunk size and buffer size that they can offload to the memcpy, using the CPU resources over to the Intel I/OAT channels for their storage application. By offloading the CPU resources for the memcpy over to the Intel I/OAT channels, the CPU can perform other tasks in parallel with the memcpy task.
Notes: 2x Intel® Xeon® processor E5-2699v4 (HT off), Intel Speed Step® enabled, Intel® Turbo Boost Technology disabled, 16x16GB DDR4 2133 MT/s, 1 DIMM per channel, Ubuntu* 16.04 LTS, Linux kernel 4.4.0-21-generic, 1 TB Western Digital* (WD1002FAEX), 1 Intel® SSD P3700 Series (SSDPEDMD400G4), 22x per CPU socket. Performance measured by the written sample application in this article.
Conclusion
This tutorial and sample application shows one way to incorporate SPDK and the Intel I/OAT feature into your storage application. The example shows how to prepare the buffers and perform the memory copy, along with hardware configuration and full build instructions. SPDK provides the Intel QuickData Technology drivers, and helps you quickly adopt your application to run on Intel® architecture with Intel I/OAT.
Other Useful Links
Authors
- Thai Le is a software engineer who focuses on cloud computing and performance computing analysis at Intel.
- Steven Briscoe is an application engineer focusing on cloud computing within the Software Services Group at Intel Corporation (UK).
- Jonathan Stern is an applications engineer and solutions architect who works to support storage acceleration software at Intel.