Overview
Face recognition has been used in a broad range of applications such as Security Systems, Marketing and Social Media, for a long time. With the increase of model complexity and hardware technologies a new era of face recognition has begun: Facial Expression Recognition. Deep learning has become essential for achieving state-of-art levels of accuracy and providing robust solutions for recognizing expressions even in different conditions of brightness, contrast and image quality.
This paper focus on the inference optimization process of a facial expression recognition system based on InceptionV3 and MobileNet architectures. It uses Intel® OpenVINO™ to enable real-time applications perform classifications using Deep-Learning models. Two experiments are defined:
- Inference using InceptionV3 architecture in Intel® Core™ i7 and Intel® Xeon® 8153.
- Inference using MobileNet architecture in Intel® Core™ i7 and Intel® Xeon® 8153.
Solution Architecture and Design
The solution is aimed at classifying the face expression class. The block diagram is shown below:
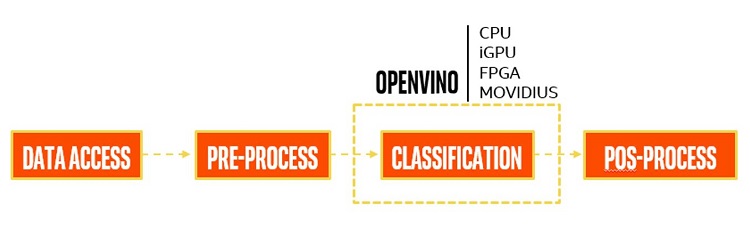
OpenVINO™
OpenVINO™ is a toolkit that allow developers to deploy pre-trained deep learning models. It has two principal modules: A Model Optimizer and the Inference Engine. Check Install Intel® Distribution of OpenVINO™ toolkit for Linux*1 for more information on how to install the SDK.
Model Optimizer
A set of command line tools that allows you to import trained models from many deep learning frameworks such as Caffe*, TensorFlow* and others (supports over 100 public models)
- Transform the model into an intermediate representation (IR) to allow the usage of the Inference Engine.
- Model conversion: Fuse operations, apply quantization to reduce data length and prepare the data with channel reordering.
Inference Engine
Uses an API based code to do inferences on the platform of your choice: CPU, GPU, VPU, or FPGA.
- Execute different layers on different devices
- Optimize execution (computational graph analysis, scheduling, and model compression)
Steps to Enable OpenVINO™ Using a TensorFlow* Model
- Convert the model to an Intermediate Representation (IR)
- Pre-process the image
- Setup the Inference Engine code to run the IR.
Creating OpenVINO™ representation
Step 1. Convert the model to an Intermediate Representation (IR)
python3
/opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo_tf.py --input_model frozen.pb \
--input_shape [1,299,299,3] \
--data_type FP32
# The following files will be created:
# frozen.bin
# frozen.xml
def pre_process_image(imagePath):
# Model input format
n, c, h, w = [1, 3, 299, 299] (InceptionV3)
image = Image.open(imagePath)
processedImg = image.resize((h, w), resample=Image.BILINEAR)
# Normalize to keep data between 0 – 1
processedImg = (np.array(processedImg) - 0) / 255.0
# Change data layout from HWC to CHW
processedImg = processedImg.transpose((2, 0, 1))
processingImg = processingImg.reshape((n, c, h, w))
return image, processingImg, imagePath
Step 2. Pre-process the image
# Plugin initialization for specified device and load extensions library if specified.
# Devices: GPU (intel), CPU, MYRIAD
plugin = IEPlugin("GPU", plugin_dirs=plugin_dir)
# Read IR
net = IENetwork.from_ir(model=model_xml, weights=model_bin)
assert len(net.inputs.keys()) == 1,
assert len(net.outputs) == 1,
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
# Load network to the plugin
exec_net = plugin.load(network=net)
del net
# Run inference
image, processedImg, imagePath = pre_process_image(fileName)
res = exec_net.infer(inputs={input_blob: processedImg})
# Access the results and get the index of the highest confidence score
res = res['dense_2/Sigmoid']
idx = np.argsort(res[0])[-1]
Hardware Configuration
The following are the hardware configurations used for the experiments:
| Intel® Xeon® Platinum 8153 processor | Intel® NUC7i7BNH | ||
|---|---|---|---|
| Architecture: | x86_64 | Architecture: | x86_64 |
| CPU op-mode(s): | 32-bit, 64-bit | CPU op-mode(s): | 32-bit, 64-bit |
| Byte Order: | Little Endian | Byte Order: | Little Endian |
| CPU(s): | 64 | CPU(s): | 4 |
| On-line CPU(s) list: | 0-63 | On-line CPU(s) list: | 0-3 |
| Thread(s) per core: | 2 | Thread(s) per core: | 2 |
| Core(s) per socket: | 16 | Core(s) per socket: | 2 |
| Socket(s): | 2 | Socket(s): | 1 |
| NUMA node(s): | 2 | NUMA node(s): | 1 |
| Vendor ID: | GenuineIntel | Vendor ID: | GenuineIntel |
| CPU family: | 6 | CPU family: | 6 |
| Model: | 85 | Model: | 142 |
| Model name: | Intel® Xeon® Platinum CPU 8153 @ 2.00GHz | Model name: | Intel® Core™ i7-7567U @ 3.50GHz |
| Stepping: | 4 | Stepping: | 9 |
| CPU MHz: | 1800 | CPU MHz: | 4000 |
| BogoMIPS: | 4000 | BogoMIPS: | 7000 |
| L1d cache: | 32K | L1d cache: | 32K |
| L1i cache: | 32K | L1i cache: | 32K |
| L2 cache: | 1024K | L2 cache: | 256K |
| L3 cache: | 22528K | L3 cache: | 4096K |
Software Used
The following is the software configuration used:
| OS | CentOS* Linux release 7.4.1708 (Core) |
| Kernel Version | kernel 3.10.0-693.el7.x86_64 |
| Python* Version | Python* 3.6.1 |
| TensorFlow* Version | 1.10 |
| Anaconda* Version | 4.3.25 |
| OpenVINO™ SDK Version | 2018.3.343 |
Results
The first assessment done within OpenVINO™ Toolkit was based on InceptionV3 topology. The results demonstrated an increase up to 7.12x improvement in inference time running on integrated Intel Graphic Processing Unit (iGPU) of an Intel® NUC7i7BNH.

For the MobileNet topology, the inference process had a performance improvement by 18.33x, as the topology is lighter than InceptionV3.

To take advantage of the full resources of the CPU, multi-inference was used to share the workload across the cores to reduce memory overhead and thereby increasing throughput and decreasing inference time by effective parallelization. After further optimization with OpenVINO™ Toolkit, the performance improved to 25.85X using multi-inferences (up-to 16 processes at the same time on a single node).
# Execute multi-inference according to the number of cores available in the hardware (in this case, 64 cores are available)
CMD="python yourScript.py”
# 4 Cores / process(16)
numactl -C 0-1,2-3 $CMD & numactl -C 4-5,6-7 $CMD &
numactl -C 8-9,10-11 $CMD & numactl -C 12-13,14-15 $CMD &
numactl -C 16-17,18-19 $CMD & numactl -C 20-21,22-23 $CMD &
numactl -C 24-25,26-27 $CMD & numactl -C 28-29,30-31 $CMD &
numactl -C 32-33,34-35 $CMD & numactl -C 36-37,38-39 $CMD &
numactl -C 40-41,42-43 $CMD & numactl -C 44-45,46-47 $CMD &
numactl -C 48-49,50-51 $CMD & numactl -C 52-53,54-55 $CMD &
numactl -C 56-57,58-59 $CMD & numactl -C 60-61,62-63 $CMD &

The same optimization was repeated using the MobileNet topology where the gains were even better, reaching a speed-up of 95.64X using multi-inferences.

Conclusion
This paper showed that is possible to speed-up the inference process by 95.64x using OpenVINO™ toolkit and Intel® Xeon® Platinum 8153 processor. It covered the steps required to transform the original model to an optimized model and provided a sample of the pre-processing and inference script. Moreover, the usage of multi-inference increases the throughput resulting on inference time reduction.
References
1. Install Intel® Distribution of OpenVINO™ toolkit for Linux*