What Is ADR?
One of the challenges for persistent memory (PMem) applications is that not all the memory hierarchy in the system is persistent. Systems supporting PMem today must have a mechanism called Asynchronous DRAM Refresh (ADR). ADR ensures that, during a power loss, all pending writes sitting on the write pending queues (WPQs) of the memory controller are written to PMem. In addition, ADR places DRAM in self-refresh mode. Given that some non-volatile dual in-line memory modules (NVDIMMs) are composed of both DRAM and flash chips, self-refresh is key to ensuring data in DRAM is in a “safe” state before it is backed up to flash.
Since ADR protects the memory controller but leaves out the CPU caches, PMem programming with ADR is not as intuitive as regular (that is, volatile) programming. Programmers must ensure that cache lines with data that should be persisted are flushed precisely at the right time and in the desired order. Getting this right is challenging and can have a performance impact. Extended ADR (eADR), which is supported in the 3rd generation Intel® Xeon® Scalable Processors, solves this problem by making sure that CPU caches are also included in the so called “power fail protected domain”. See Figure 1.
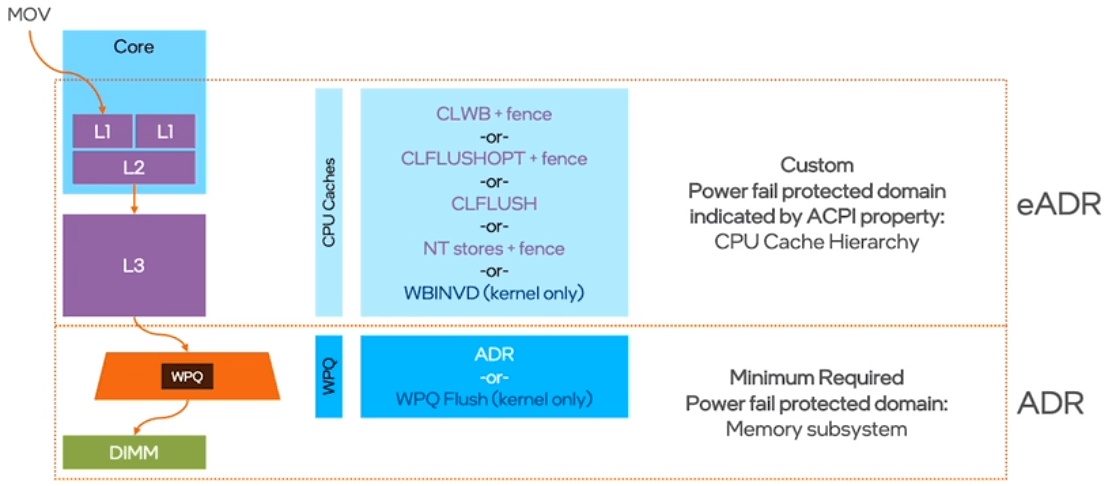
With ADR, programmers must use any of the available instructions—such as CLWB or CLFLUSH—to make sure data is persistent. With eADR, on the other hand, no flushing is necessary, simplifying PMem programming as a result.
Notes on Performance
The most apparent advantage that eADR has over ADR is simplifying PMem programming. Realize, however, that during the transition from ADR to eADR, there will be servers with only ADR and servers that will have both. It is then the application’s responsibility to detect the platform’s capabilities where it is running and implement the logic that avoids flushing only when eADR is present. If you use any of the libraries from the Persistent Memory Development Kit (PMDK), all this is already done for you.
There are also advantages related to performance. These are two areas where eADR will help:
- Eliminating the need to wait for flushes to finish: This is the principal benefit. Flushing instructions have a performance impact. Even when out-of-order instructions—such as CLWB or CLFLUSHOPT—are used, the application may need, at some point, to make sure previous writes reached persistent media before continuing execution (issuing a fence instruction).
- Eliminating the need to flush data with temporal locality: Instructions for flushing data out of the CPU caches, such as CLFLUSH, were never designed with the PMem use case in mind. In the volatile world, flushing data out of the CPU caches is a proactive action that the application takes to remove data from the cache that is no longer needed (no longer has temporal locality). That is, flushing a cache line invalidates it. However, in the PMem world, flushing data to make sure it is persistent does not necessarily mean we want to also invalidate the cache line.
Note: Eliminating the need to flush data with temporal locality is only an advantage when instructions other than CLWB are used for flushing. This is because CLWB will be improved in the 3rd generation of Intel® Xeon® Scalable Processors. CLWB will be able to flush local—same NUMA node—cache lines without invalidating them; a CLWB issued for a remote cache line will still invalidate it.
Finally, it is important to point out that applications doing writes using non-temporal stores will not see any performance benefit with eADR. Non-temporal stores bypass the CPU caches, so no flushing is necessary anyway.
Lock-free programming, an Example
A nice PMem feature enabled by eADR is the fact that visibility is equalized with persistence. This means that if a write is globally visible, it is persistent. Lock-free programming with PMem without awkward—and performance degrading—workarounds such as flush-on-read or tagging is then possible. eADR is especially promising in the world of in-memory databases, making it possible to implement fast and persistent lock-free index data structures as if they were volatile.
To showcase this potential, we implemented three versions of a lock-free algorithm: (1) baseline (ADR + invalidating flushing), (2) CLWB (ADR + non-invalidating flushing), and (3) eADR (no flushing required). The algorithm is a simple single-producer single-consumer ring buffer. Results are shown in Figure 2.
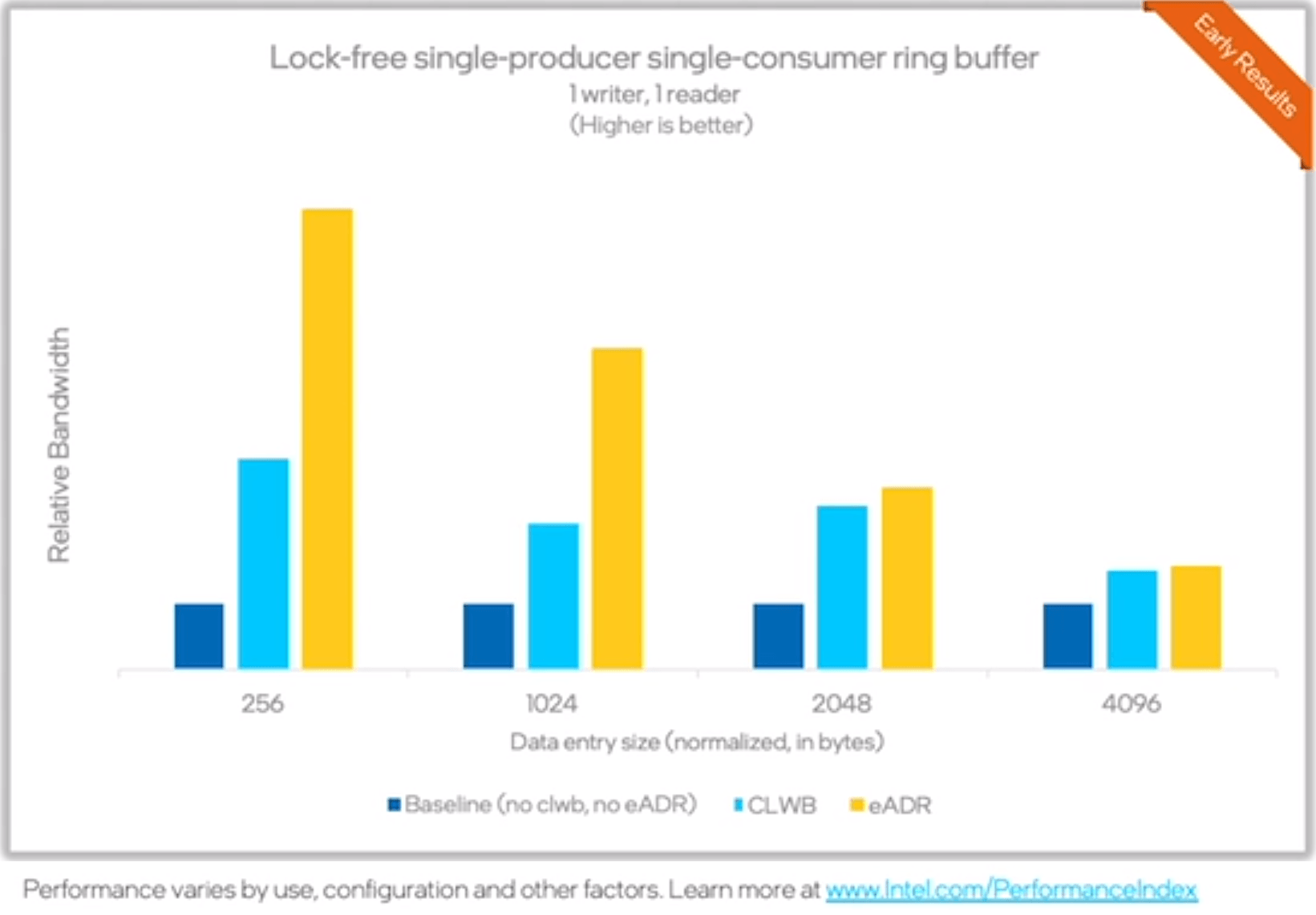
Realize that the results shown in Figure 2 are relative to the baseline, which has a value of one. As it is possible to see, the higher gains are for the smaller updates. CLWB triples the baseline bandwidth for the 256 bytes case, and eADR can more than double the CLWB case’s performance (six times the baseline performance).
To Learn More
To learn more about eADR and other useful introductory topics related to PMem programming, I recommend that you watch the following video by Andy Rudoff—the persistent memory storage architect in the Intel Optane group. The images used in this article were extracted from that video.

Summary
This short article covered eADR, the new feature available in the 3rd generation Intel® Xeon® Scalable Processors (code named Ice Lake). We went over what eADR is, how it can help PMem programmers, and its potential performance benefits compared to ADR and flushing. Performance numbers were shown to showcase the latter, comparing eADR with ADR for a lock-free single-producer single-consumer ring buffer.
"