Get the Latest on All Things CODE
Sign Up
Data scientists tackle a wide array of everyday problems—from healthcare to finance to Netflix* show ratings—using data-driven decision-making. They employ various tools such as the popular pandas, scikit-learn*, and TensorFlow* frameworks to handle data preprocessing, classical machine learning, and deep learning to make their models and visualizations more accurate. Given that most analytics workflows are data- and compute-intensive, how can the time-to-solution be reduced without putting too much burden on data scientists to modify their code? This article illustrates how Intel’s latest AI software optimizations drastically improve data analytics performance on platforms based on Intel® processors with minimal code changes.
Intel® Distribution of Modin*
Let's start with pandas, the popular Python* data preprocessing and analysis library beloved by data scientists for its ease of use. The latest version only runs on a single core, even though modern processors offer a lot of cores per processor. Preprocessing can go from minutes to hours or even days as the data size increases. Lack of scaling causes many data scientists to give up on pandas and switch to another framework like Apache Spark*. Unlike pandas, however, Spark is not as user friendly and usually requires data scientists to modify their workflows.
Intel has a better solution for seamless scaling. Modin* provides a simple solution that supports the pandas API. Intel® Distribution of Modin*, with its powerful OmniSci* back end, provides a scalable pandas API with a one-line code change:

The performance improvement for the common New York City (NYC) Taxi dataset (approximately 1.1 billion individual taxi trips in the city) is significant:

For more details, Data Science at Scale with Modin.
Intel® Extension for Scikit-learn*
After preprocessing, the next step in the data science pipeline is often data modeling with the popular scikit-learn machine-learning library. Like pandas, scikit-learn doesn’t take advantage of instruction- or thread-level parallelism. Using Intel® Extension for Scikit-learn* can significantly speed up machine learning performance (38x on average and up to 200x depending on the algorithm) by changing only two lines of code:


For more details, see:
- Intel Gives scikit-learn the Performance Boost Data Scientists Need
- Intel Extension for Scikit-learn documentation
Intel® Optimization for TensorFlow*
TensorFlow* is a popular framework best known for deep-learning model development and deployment. However, TensorFlow previously had not been optimized for Intel® processors. As of TensorFlow v2.5, Intel® oneAPI Deep Neural Network Library (oneDNN) is officially available as part of the official TensorFlow package. The built-in optimizations in oneDNN are enabled without code modifications. Just set an environment variable to get up to 3x speedup:

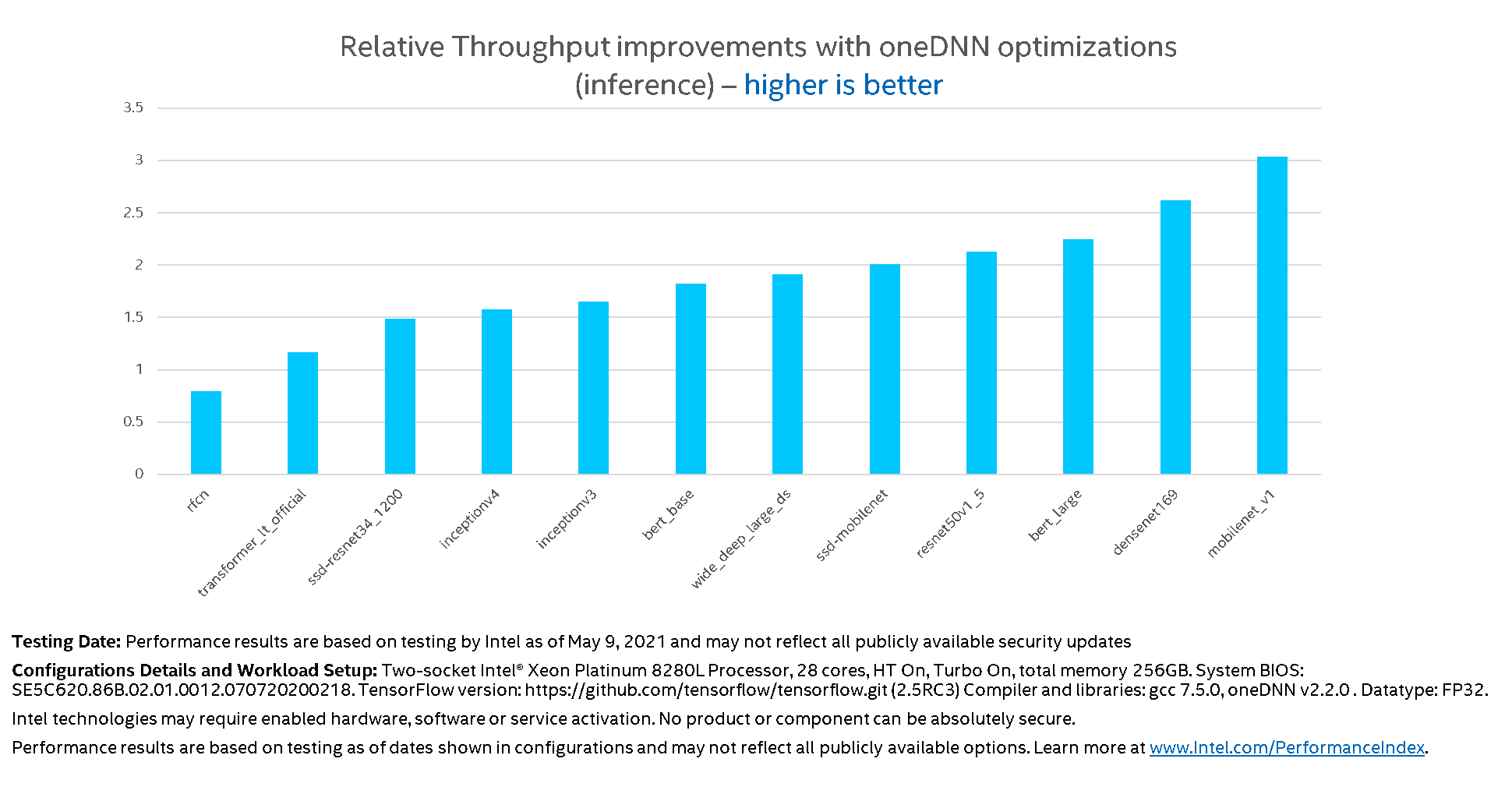
For more information, see Leverage Deep Learning Optimizations from Intel in TensorFlow.
Final Thoughts
If you are working on a complex pipeline that requires one or more of these libraries, try the Intel® oneAPI AI Analytics Toolkit. This toolkit provides a comprehensive set of interoperable Python packages, including those mentioned in this article.
For more information on how to install these tools and take advantage of these optimizations, see the following resources:
- Intel Distribution of Modin Resource Page
- Modin Documentation
- Intel Extension for Scikit-learn Get Started Guide
- Intel® Optimization for TensorFlow* Get Started Guide
- TensorFlow GitHub*
- Intel oneAPI AI Analytics Toolkit Download
- Intel oneAPI AI Analytics Toolkit Get Started Guide
- oneAPI Basics Training Series
______
You May Also Like
| Intel® oneAPI AI Analytics Toolkit Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python libraries. Get It Now See All Tools |