
With the most recent release of Chrome (M120) Google finally shipped the long-awaited f16 support for WebGPU, which allows developers to use the half-precision floating-point type f16 in WebGPU shaders (WGSL). Chrome’s F16 support was enabled with significant contributions from Intel, which “dedicated significant resources to help implement f16 in Dawn/Tint, and write proper testing coverage in the CTS,” according to Google’s Intent to Ship announcement.
In this article, we’re going to explain how f16 is supported by WebGPU and why it’s important for WebGPU application developers, particularly for AI workloads accelerated by WebGPU.
About the f16 Datatype
F16, or FP16, as it’s sometimes called, is a kind of datatype computers use to represent floating point numbers. In fact, IEEE 754 standards define several formats to support different precisions and ranges for floating point, including FP80 (extended precision), FP64 (double precision), FP32 (single precision), and FP16 (half precision). In general, the number here (80, 64, 32, 16) specifies how many bits are used to represent one floating point number in computer memory. The following diagram shows how an FP16 floating point number is stored in memory:
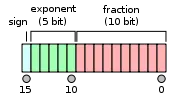
The memory format of an IEEE 754 half precision floating point value.
Intuitively, more fraction bits can achieve higher precision while more exponent bits can represent wider dynamic range. Although modern computation devices have built-in support for all of these standard floating point formats [1], it turns out that for deep learning training, precision is not as important as the dynamic ranges , which is why FP80 is never used in deep learning and why some companies, like Google, invented other FP formats, like BFLOAT16, in favor of wider dynamic ranges. (For AI inference workloads used for edge device deployment, some simple integer-based quantizations are important, thus integer data types like Int16/Int8 are desired [4]).
Compared to high precision formats, F16 has higher computation peak performance while utilizing less memory for data communication and storage, resulting in reduced power consumption. Given these benefits, you can see why F16 support is highly requested by many AI frameworks and runtimes.
How WebGPU Supports f16
Usually, WebGPU applications have two building blocks—one is the web application logic, which has the standard web artifacts like JavaScript (including WebGPU APIs), HTML, CSS, and other resources; the other is called WebGPU Shaders, which is written in WGSL (WebGPU Shading Languages) and is unique to WebGPU applications. You can refer to any good WebGPU tutorial, like WebGPU Fundamentals, to learn more about the details, but conceptually WebGPU JavaScript APIs are responsible for GPU device management, memory buffer management, and GPU Pipeline management, while shaders are functions that are executed by the GPU to compute vertex positions (Vertex Shader) or pixel colors, lightings (Fragment Shader), or simply to run some parallel computations on GPUs (Computing Shader).
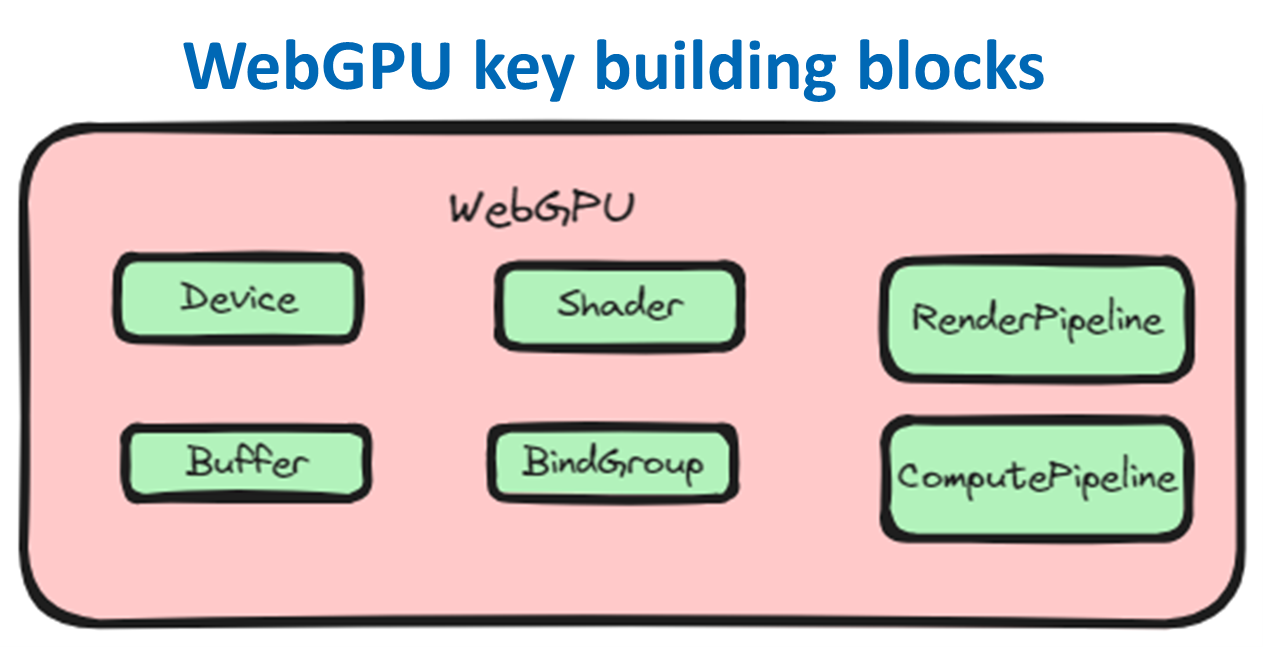
This illustration shows the key building blocks comprising the WebGPU API. In this illustration, “Device” is the logical instantiation of an adapter; “Buffer” represents a block of memory that can be accessed by GPU; “Shader” is the code executed by GPU to calculate color, lighting, or do parallel computation; “RenderPipeline” is a kind of pipeline that controls the vertex and fragment shader stages; “ComputePipeline” is a kind of pipeline that controls the compute shader stage; and “BindGroup” defines how a set of resources are bound together.
WGSL is a kind of static type programming language and in that sense it’s similar to C++, Rust, etc. So, it’s easy to understand that WGSL has pre-defined several built-in datatypes like i32 (a 32-bit signed integer), u32 (a 32-bit unsigned integer), f32 (a 32-bit floating-point number), bool (a Boolean value), and now supports f16 as another built-in datatype. Here’s a sample of the type of code that you’ll be able to write:
@vertex fn vs(
@builtin(vertex_index) vertexIndex : u32
) -> @builtin(position) vec4f {
var a:f16 = 0.8;
var b:f16 = 1.0;
let pos = array(
vec2f( a, 0.5), // top center
vec2f(-0.5, b), // bottom left
vec2f( 0.5, -0.5) // bottom right
);
return vec4f(pos[vertexIndex], 0.0, 1.0);
}
Keep in mind when coding that not all browsers will support the f16 datatype and your code needs to account for that. F16 support in WGSL is defined as an optional feature. Developers can query the availability of this feature by querying 'shader-f16' as the GPUFeatureName specified in the WebGPU spec and then using the 'f16' extension from the WGSL spec to access 16-bit floating point variables and APIs in their shader code.
The Performance Impact of f16
As expected, supporting f16 will deliver a a significant performance boost for AI workloads through reduced memory usage and lowered power consumption. As referenced in Google’s original Intent to Ship: WebGPU f16 support, multiple benchmarks and demos have shown performance benefits of up to 25% for ALU bound tasks and a whopping 50% for memory bound tasks. TensorFlow.js has been investigating using f16 in WebGPU and already has it available in the WebGL implementation. TensorFlow.js has already seen significant improvements from enforcing the use of Half Float (the GL equivalent feature).
WebGPU unlocks many GPU programming possibilities in the browser. It reflects how modern GPU hardware works and serves as a foundation for more advanced GPU capabilities in the future. The evolution of web technology is driving innovation and creating new opportunities for businesses and individuals alike. With the new f16 datatype introduced by WebGPU, developers should be able to deliver even more AI, immersive, and accessible browser-based applications.
About the Author
Qi Zhang is the director of the Web Platform Engineering team of Intel China System Software Engineering Group, leading a team to enable and optimize web technology for Intel platforms, including key runtime components of Chromium including V8, WebAssembly, Blink, and key Web API development tools such as l WebGPU, WebRTC, and WebNN. The author would like to thank all the valuable review feedback from Ezequiel Lanza, Nikki McDonald, Barbara Hochgesang and Yang Gu.