Introduction
Vectorization Advisor is a vectorization optimization tool that lets you identify loops that will benefit most from vectorization, identify what is blocking effective vectorization, explore the benefit of alternative data reorganizations, and increase the confidence that vectorization is safe.
Intel provides an optimized ready-to-use math library containing a rich set of popularly used mathematical routines called Intel® oneAPI Math Kernel Library (oneMKL:/content/www/cn/zh/develop/tools/math-kernel-library.html) to achieve higher application performance and reduce development time.
Intel® Advisor is now equipped with a special feature which enables developers to gather insights as to how effectively they are using Intel® oneMKL.
A simple matrix multiplication code is used here for the purpose of demonstrating the feature. For the purpose of explaining different ways of implementing Matrix multiplication and the best method of achieving it, we name the code snippets as solution 1, 2, 3, and 4 respectively
- Solution 1 is the traditional way of multiplying 2 matrices using 3 for loops. However, it turns out to be an inefficient code since it doesn’t get vectorized. Find out why and how by Intel® Advisor analysis.
- Solution 2 is a comparatively efficient way of multiplying matrices by transposing matrix (for better memory access and reuse of data loads).
- Solution 3 is yet another way of achieving the task efficiently which uses cache blocking technique for better cache usage
- Solution 4 simply replaces all the implementations with oneMKL routines which are optimized for IA and bring dramatic increase in performance.
Step 1:
Create a new project and chose the application you want to analyze.
Scroll down and be sure that “Analyze MKL loops and function” checkbox is checked. This will be automatically checked in. if not checked, Intel® Advisor will not dive into MKL code
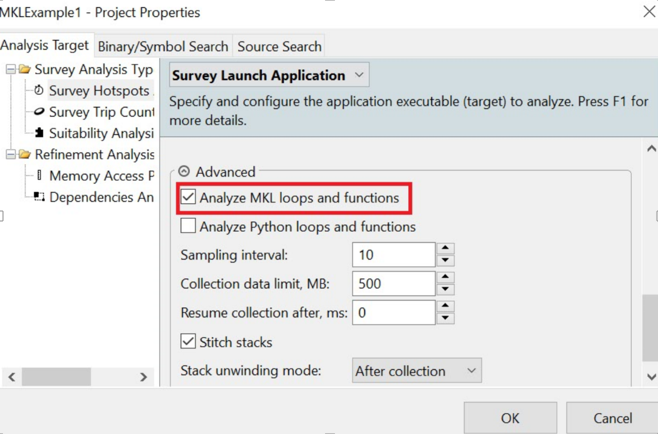
Step2:
Now, you can analyze your application by collecting and analyzing data using Intel® Advisor “Survey Target” Tab on the left hand side of the pane. Note: This might take a little longer!
Another method is using the Intel Advisor command-line to analyze your application as follows:
advixe-cl -collect survey -project-dir /user/test/testmkl /user/test/matmult
Observations: Look for the Summary tab details which gives you an overview of the applications statistics like the top time consuming loops, loop metrics which explains the breakdown of time spent in user code/ MKL code and Recommendations revealing hints to achieve better efficiency

Observation2: You can see that loop at matmul.cpp:18 is the top time consuming loop and it is scalar. Loop is a part of solution 1.
for(int k = 0; k < size; k++)
{
C[i*size + j] += A[i*size + k] * B[k*size + j];
}
Why the loop was not vectorized?
Due to cross iteration dependency (unchanged indexing of c[]) the loop remains scalar. You can follow Intel® Advisor recommendation tab which suggests for a dependency analysis.
What should be done to get this vectorized?
Note: Follow the Intel® Advisor recommendations to vectorize the loop by going for a dependencies analysis. In the performance issues column, Intel® Advisor points out that there is an assumed dependency and the compiler did not auto vectorize the loop.
Solution: when you do the dependencies analysis you determined whether a dependency is real. Now you have to make the source code changes in order to vectorize the loop.
Go back and take a look at the next hotspot: Loop at matmul.cpp: 30
You notice that loop at 30 takes significant amount of time. Note that this loops is found in solution2. Unlike the previous loop, there is no cross iteration dependency for c and hence the loop is vectorized.
What can be done to improve the efficiency?
Generally outer loops are not vectorized. Hence interchanging the loops to achieve vectorization and the efficiency increases.
Go back and take a look at the next hotspot: Loop at matmul: 48
Note that this loop is found in solution3. It is the inner most loop of blocked implementation.Blocking is the classic way of improving cache usage. The code is not cache friendly and blocking is a classic way of improving cache usage.
The above three solutions require developer efforts in order to improve performance. However, oneMKL has a ready set of routines which address these optimization techniques (like parallelisation/ Vectorization). Notice the dramatic change in performance when these implementations are replaced by oneMKL routines. Advisor can now deep dive into MKL code and exhibit if the user is using these routines efficiently.
Return back to the Survey and roofline tab, and press the MKL button (see screen shot below) on the top pane. This displays all the MKL loops along with the statistics.
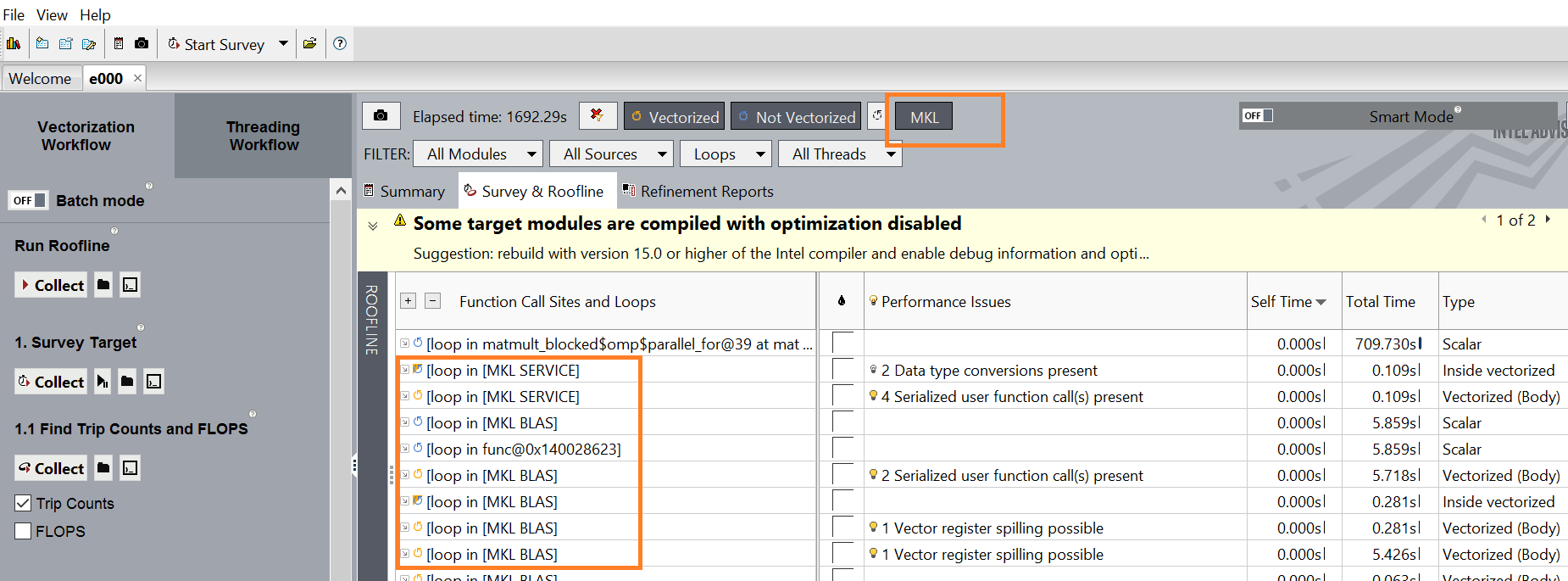
Self-time of the loop would be an ideal metric to measure the efficiency of the loop and you can notice that loops in [MKL BLAS] and loops in [MKL SERVICE] take the minimal time compared to the previous implementations.
Roofline Analysis of loops:
A Roofline chart is a visual representation of application performance in relation to hardware limitations, including memory bandwidth and computational peaks.
Collect this data by pushing “Run Roofline” button on the LHS. or my running the Intel Advisor command-line as shown below:
advixe-cl -collect roofline -project-dir /user/test/testmkl /user/test/matmult

Matmul.cpp:18 0.11 GFLOPS (matmul_naive) Red dot
Matmul.cpp:30 0.76 GFLOPS (matmul_transposed) yellow dot
Matmul.cpp:48 0.66 GFLOPS (matmul_blocked) yellow dot
MKL BLAS 8.2 GFLOPS (ccblas_dgemm) green dot
MKL BLAS 31.94 GFLOPS (ccblas_dgemm) green dot
The size and color of the dots in Intel® Advisor’s Roofline chart indicates how much of the total program time a loop or function takes.
Small, green dots take up relatively little time, hence are likely not worth optimizing. Large, red dots consume most of the execution time and hence the best candidates for optimization are the large, red dots with a large amount of space between them and the topmost roofs.
Summary: Discover the usability of core math functions from the Intel® oneAPI Math Kernel Library (oneMKL) to improve the performance of your application and the analysis is now made easy with Intel® Advisor's new feature to analyze MKL code.
"