Meet the Intel®-Optimized Frameworks That Make It Easier
Nathan Greeneltch and Jing Xu, software technical consulting engineers, Intel Corporation
@IntelDevTools
When you're developing AI applications, you need highly optimized deep-learning models that enable an application to run wherever it's needed and on any kind of device—from the edge to the cloud. But optimizing deep-learning models for higher performance on CPUs presents some challenges, like:
- Code refactoring to take advantage of modern vector instructions
- Use of all available cores
- Cache blocking
- Balanced use of prefetching
- And more
These challenges aren’t significantly different from those you see when you're optimizing other performance-sensitive applications—and developers and data scientists can find a wealth of deep learning frameworks to help address them. Intel has developed several optimized deep-learning primitives to use inside these popular deep-learning frameworks to ensure you're implementing common building blocks efficiently through libraries like Intel® Math Kernel Library (Intel® MKL).
This article:
- Looks at the performance of Intel's optimizations for frameworks like Caffe*, TensorFlow*, and MXNet*.
- Introduces the type of accelerations available on these frameworks via the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN).
- Shows how to acquire and build these framework packages with Intel's accelerations. This helps you take advantage of accelerated CPU training and inference execution with no code changes (Figures 1 and 2).

Figure 1. Deliver significant AI performance with hardware and software optimizations on Intel® Xeon® Scalable processors.

Figure 2. Boost your deep-learning performance on Intel Xeon Scalable processors with Intel® Optimization for TensorFlow* and Intel MKL-DNN.
Intel® MKL-DNN
This open-source performance library accelerates deep-learning applications and frameworks on Intel® architectures. Intel MKL-DNN contains vectorized and threaded building blocks that you can use to implement deep neural networks (DNN) with C and C++ interfaces (Table 1).
The performance benefit from Intel MKL-DNN primitives is tied directly to the level of integration to which the framework developers commit (Figure 3). There are reorder penalties for converting input data into Intel MKL-DNN preferred formats. So, framework developers benefit from converting once and then staying in Intel MKL-DNN format for as much of the computation as possible.
Also, two-in-one and three-in-one fused versions of layer primitives are available if a framework developer wants to use the power of the library. The fused layers allow for Intel MKL-DNN math to run concurrently on downstream layers if the relevant upstream computations are completed for that piece of the data or image frame. A fused primitive includes compute-intensive operations along with bandwidth-limited operations.
Table 1. What's included in Intel MKL-DNN
| Function | Features |
|---|---|
| Compute-intensive operations |
|
| Memory-bound operations |
|
| Data manipulation |
|
| Primitive fusion |
|
| Data types |
|
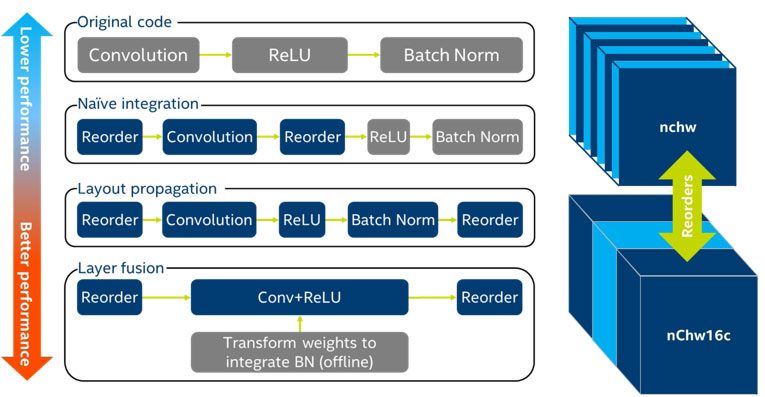
Figure 3. Performance versus level of integration and Intel MKL-DNN data format visualization
Install Intel MKL-DNN
Intel MKL-DNN is distributed in source-code form under the Apache* license, v2.0. For up-to-date build instructions for Linux*, macOS*, and Windows*, see the Read Me.
The VTUNEROOT flag is required for integration with Intel® VTune™ Profiler. The Read Me explains how to use this flag.
Install Intel®-Optimized Frameworks
Intel® Optimization for TensorFlow*
Current distribution channels are PIP*, Anaconda*, Docker*, and build from source. See the Intel® Optimization for TensorFlow* Installation Guide for detailed instructions for all channels.
Anaconda – Linux:
conda install -c defaults tensorflow
Anaconda – Windows:
conda install tensorflow-mkl -c defaults
Intel® Optimization for Caffe*
Intel has a tutorial showing how to use the following:
- Build Caffe optimized for Intel architecture
- Train deep-network models using one or more compute nodes
- Deploy networks
(Ubuntu 16.04)
git clone https://github.com/intel/caffe.git
Open a Terminal window
sudo apt-get update
sudo apt-get install build-essential cmake git pkg-config
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev
libhdf5-serial-dev protobuf-compiler
sudo apt-get install libatlas-base-dev
sudo apt-get install ––no-install-recommends libboost-all-dev
sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
sudo apt-get install libopencv-dev
Go to Caffe root directory.
cp Makefile.config.example Makefile.config
vi Makefile.config (add the red part)
INCLUDE DIRS := $(PYTHON INCLUDE) /usr/local/include /usr/include/hdf5/serial
LIBRARY DIRS := $(PYTHON LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-
linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial
make all -j4
Intel® Optimized Apache MXNet*
For more details on this library, see:
Intel® Optimized Apache MXNet*
git clone ––recursive https://github.com/apache/incubator-mxnet.git
cd mxnet && make -j $(nproc) USE_OPENCV=1 USE_BLAS=mk1 USE MKLDNN=1
Performance Considerations and Runtime Settings
Now let's consider TensorFlow runtime settings for best performance―specifically, convolutional neural network (CNN) inference. The concepts can be applied to other frameworks accelerated with Intel MKL-DNN and other use cases. However, some empirical testing is required. Where necessary, different recommendations are given for real-time inference (RTI) with a batch size of 1 and maximum throughput (MxT) with a tunable batch size.
Maximum Throughput versus Real-Time Inference
Deep-learning inference is usually done with two different strategies, each with different performance measurements and recommendations:
- MxT processes many images per second, passing in batches of size that's greater than 1. You can achieve the best performance by exercising all the physical cores on a socket. This solution is intuitive: Load up the CPU with as much work as possible, and process as many images as possible in a parallel and vectorized fashion.
- RTI is a different scenario where a single image needs to be processed as quickly as possible. The goal is to avoid penalties from excessive thread launching and orchestration between concurrent processes. The strategy is to confine and run them quickly.
Let's discuss some best-known methods (BKMs) for maximizing MxT and RTI performance.
TensorFlow Runtime Options Affecting Performance
These runtime options heavily affect TensorFlow performance. Understanding them helps you get the best performance out of Intel optimizations. BKMs differ for MxT and RTI. The runtime options are: {intra|inter}_op_parallelism_threads and data layout.
{intra|inter}_op_parallelism_threads
- Recommended settings (MxT): intra_op_parallelism = #physical cores
- Recommended settings (RTI): intra_op_parallelism = #physical cores
- Recommended settings for inter_op_parallelism: 2
- Use (shell):
python script.py ––num_intra_threads=cores ––num_inter_threads=2 ––mkl=True
intra_op_parallelism_threads and inter_op_parallelism_threads are environment variables defined in tensorflow.ConfigProto. The ConfigProto is used for configuration when creating a session. These two environment variables control number of cores to use.
The intra_op_parallelism_threads environment variable controls parallelism inside an operation. For instance, if matrix multiplication or reduction is intended to run in several threads, set this environment variable. TensorFlow schedules tasks in a thread pool that contains intra_op_parallelism_threads. OpenMP* threads are bound to thread context as closely as possible on different cores. Setting this environment variable to the number of available physical cores is recommended.
The inter_op_parallelism_threads environment variable controls parallelism among independent operations. Since these operations are not relevant to each other, TensorFlow attempts to run them concurrently in the thread pool that contains inter_op_parallelism_threads. To minimize effects that are brought to intra_op_parallelsim_threads, this environment variable is recommended to be set to the number of sockets where you want the code to run. For the Intel Optimization of TensorFlow, it's recommended to keep the entire execution on a single socket.
Data Layout
- Recommended settings: Data_format = NCHW
- Use (shell):
python script.py ––num_intra_threads=cores ––num_inter_threads=2 ––mkl=True data_format=NCHW
In modern Intel architectures, efficient use of cache and memory greatly impacts overall performance. A good memory access pattern minimizes the performance cost of accessing data in memory. To achieve this, it's important to consider how data is stored and accessed. This is usually referred to as data layout. It describes how multidimensional arrays are stored linearly in the memory address space.
Usually, data layout is represented by four letters for a two-dimensional image.
- N: Batch size, indicating number of images in a batch
- C: Channel, indicating number of channels in an image
- W: Width, indicating number of pixels in horizontal dimension of an image
- H: Height, indicating number of pixels in vertical dimension of an image

Figure 4. Data format and layout: NHWC versus NCHW
That Affect Performance
The order of these four letters indicates how pixel data is stored in 1D memory space. For instance, NCHW indicates pixel data is stored in this order: width-wise, height-wise, channel-wise, and batch-wise (Figure 4). The data is then accessed from left to right with channels-first indexing. NCHW is the recommended data layout for Intel MKL-DNN because this is an efficient layout for the CPU. TensorFlow uses NHWC as the default data layout, but it also supports NCHW.
NUMA Controls
- Recommended settings: ––cpunodebind=0 ––membind=0
- Usage (shell):
numactl ––cpunodebind=0 ––membind=0 python script.py ––num_intra_threads=cores ––num_inter_threads=2 ––mkl=True data_format=NCHW
Running on a non-uniform memory access (NUMA) enabled machine brings with it special considerations. NUMA is a memory layout design used in data center machines that take advantage of locality of memory in multisocket machines with multiple memory controllers and blocks. The Intel Optimization for TensorFlow runs best when confining both running and memory use to a single NUMA node.
Intel MKL-DNN Technical Performance Considerations
The library takes advantage of single instruction multiple data (SIMD) instructions through vectorization, and multiple cores through multithreading. Vectorization effectively uses cache and the latest instruction sets. On modern Intel® processors, a single core can perform up to two fused multiply and add (FMA) operations on 16 single-precision or 64 Int8 numbers per cycle. Also, the technique of multithreading helps in performing multiple independent operations simultaneously. Since deep-learning tasks are often independent, getting available cores working in parallel is an obvious choice to boost performance.
To achieve the best possible CPU use, Intel MKL-DNN may use hardware-specific buffer layouts for compute-intensive operations, including convolution and inner product. All the other operations run on the buffers in hardware-specific layouts or common layouts used by frameworks.
Intel MKL-DNN uses OpenMP to express parallelism. OpenMP is controlled by various environment variables: KMP_AFFINITY, KMP_BLOCKTIME, OMP_NUM_THREADS, and KMP_SETTINGS. These environment variables are described in the following sections. Changing the values of these environment variables affects performance of the framework, so we highly recommend that users tune them for their specific neural network model and platform.
KMP_AFFINITY
- Recommended settings:
KMP_AFFINITY=granularity=fine,verbose,compact,1,0 - Usage (shell):
numactl ––cpunodebind=0 ––membind=0 python script.py ––num_intra_ threads=cores ––num_inter_threads=2 ––mkl=True data_format=NCHW ––kmp_affinity=granularity=fine,verbose,compact,1,0
KMP_AFFINITY is used to restrict running certain threads to a subset of the physical processing units in a multiprocessor computer. Set this environment variable as follows:
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]
- Modifier is a string consisting of a keyword and specifier.
- Type is a string indicating the thread affinity to use.
- Permute is a positive integer value that controls which levels are most significant when sorting the machine topology map. The value forces the mappings to make the specified number of most significant levels of the sort the least significant, and then inverts the order of significance. The root node of the tree is not considered a separate level for the sort operations.
- Offset is a positive integer value that indicates the starting position for thread assignment.
As an example to explain basic content of this environment variable, use the recommended setting of KMP_AFFINITY:
KMP_AFFINITY=granularity=fine,verbose,compact,1,0
The modifier is granularity=fine,verbose. The word fine causes each OpenMP thread to be bound to a single-thread context, and verbose prints messages concerning the supported affinity, for example:
- The number of packages
- The number of cores in each package
- The number of thread contexts for each core
- OpenMP thread bindings to physical thread contexts
The word compact is the value of type, assigning the OpenMP thread <n>+1 to a free thread context as close as possible to the thread context where the <n> OpenMP thread was placed.
Figure 5 shows the machine topology map when KMP_AFFINITY is set to these values. The OpenMP thread <n>+1 is bound to a thread context as closely as possible to the OpenMP thread <n>, but on a different core. Once each core has been assigned an OpenMP thread, the subsequent OpenMP threads are assigned to the available cores in the same order, but they are assigned on different thread contexts.

Figure 5. Machine topology map with the setting KMP_AFFINITY=granularity=fine,compact,1,0
The advantage of this setting is that consecutive threads are bound close together so that communication overhead, cache line invalidation overhead, and page thrashing are minimized. It's desirable to avoid binding multiple threads to the same core and leaving other cores unused. For more detailed description of KMP_AFFINITY, see the Intel® C++ Compiler Developer Guide and Reference.
KMP_BLOCKTIME
- Recommended settings for CNN: KMP_BLOCKTIME=0
- Recommended settings for non-CNN: KMP_BLOCKTIME=1 (user verifies empirically)
- Usage (shell):
numactl ––cpunodebind=0 ––membind=0 python script.py ––num_intra_threads=cores ––num_inter_threads=2 ––mkl=True data_format=NCHW ––kmp_affinity=granularity=fine,verbose,compact,1,0 ––kmp_blocktime=0( or 1)
This environment variable sets the time, in milliseconds, that a thread waits after completing running a parallel region before going to sleep. The default value is 200 ms.
After completing running a parallel region, threads wait for new parallel work to become available. After a certain period of time has elapsed, they become inactive. Sleeping allows the threads to be used until more parallel work becomes available, by threaded code that isn't OpenMP and may run between parallel regions, or by other applications. A small KMP_BLOCKTIME value may offer better overall performance if the application contains threaded code that isn't OpenMP that runs between parallel regions. A larger KMP_BLOCKTIME value may be more appropriate if threads are to be reserved solely for running OpenMP, but may penalize other concurrently-running OpenMP or threaded applications. The suggested setting is 0 for CNN-based models.
OMP_NUM_THREADS
- Recommended settings for CNN: OMP_NUM_THREADS = # physical cores
- Usage (shell): Export OMP_NUM_THREADS= # physical cores
This environment variable sets the maximum number of threads to use in OpenMP parallel regions if no other value is specified in the application. The value can be a single integer, in which case each integer specifies the number of threads for a parallel region at each nesting level. The first position in the list represents the outermost parallel nesting level. The default value is the number of logical processors visible to the operating system on which the program is executed. The recommended value equals the number of physical cores.
KMP_SETTINGS
- Use (shell): Export KMP_SETTINGS=TRUE
This environment variable enables (TRUE) or disables (FALSE) the printing of OpenMP runtime library environment settings when the program runs.
Learn More
Start using Intel-optimized frameworks to accelerate your deep-learning workloads on the CPU today. Access resources on www.intel.ai and get support from the Intel® AI Developer Forum. Also, visit the AI Model Zoo for solution-oriented resources for your accelerated TensorFlow projects. These resources help you use CPU resources to their fullest capability.
References
1 Inference using FP32 batch size Caffe for GoogleNet* v1 128, AlexNet v 256.
Configurations for inference throughput: Tested by Intel as of 6/7/2018. Platform: two-socket Intel® Xeon® Platinum processor, 8180 CPU at 2.50 GHz and 28 cores, HyperThreading ON, turbo ON. Total Memory: 376.28 GB (12 slots, 32 GB, 2666 MHz), four instances of the framework, CentOS* Linux*: 7.3.1611 core, SSD, sda RS3WC080, HDD 744.1 GB, sdb RS3WC080, HDD 1.5 TB, sdc RS3WC080, HDD 5.5 TB, deep-learning framework Caffe version: a3d5b022fe026e9092fc7abc7654b1162ab9940d. Topology: GoogleNet v1, BIOS: SE5C620.86B.00.01.0004.071220170215, Intel MKL DNN version: 464c268e544bae26f9b85a2acb9122c766a4c396, NoDataLayer. Measured: 1449 images per second vs. tested by Intel as of 06/15/2018. Platform: 2S Intel® Xeon® E5-2699 processor v3 at 2.30 GHz (18 cores), HyperThreading enabled, turbo disabled, scaling governor set to “performance” via the intel_pstate driver, 64 GB DDR4-2133 ECC RAM. BIOS: SE5C610.86B.01.01.0024.021320181901, CentOS Linux 7.5.1804 (core) kernel 3.10.0-862.3.2.el7.x86_64, SSD sdb INTEL SSDSC2BW24 SSD 223.6GB. Framework BVLC Caffe: GitHub*, Inference and training measured with caffe time command. For ConvNet topologies, a dummy dataset was used. For other topologies, data was stored on local storage and cached in memory before training. BVLC Caffe, revision 2a1c552b66f026c7508d390b526f2495ed3be594.
Configuration for training throughput: Tested by Intel as of 05/29/2018 Platform: two-socket Intel Xeon Platinum 8180 processor at 2.50 GHz, 28 cores, HyperThreading ON, turbo ON, total memory 376.28 GB (12 slots, 32 GB, 2666 MHz), four instances of the framework, CentOS Linux 7.3.1611 core, SSD, sda RS3WC080, HDD 744.1 GB, sdb RS3WC080, HDD 1.5TB, sdc RS3WC080, HDD 5.5TB, deep learning framework Caffe version: a3d5b022fe026e9092fc7abc765b1162ab9940d Topology: AlexNet BIOS: SE5C620.86B.00.01.0004.071220170215, Intel MKL DNN version: 464c268e544bae26f9b85a2acb9122c766a4c396 NoDataLayer. Measured: 1257 imgages per sec vs. tested by Intel as of 06/15/2018. Platform: 2S Intel Xeon E5-2699 processor v3 at 2.30 GHz (18 cores), HyperThreading enabled, turbo disabled, scaling governor set to performance via the intel_pstate driver, 64 GB, DDR4-2133 ECC RAM. BIOS: SE5C610.86B.01.01.0024.021320181901, CentOS Linux 7.5.1804 (core) kernel 3.10.0-862.3.2.el7.x86_64, SSD, sdb INTEL SSDSC2BW24, SSD 223.6 GB. Framework: BVLC Caffe. Inference and training measured with caffe time command. For ConvNet topologies, dummy dataset was used. For other topologies, data was stored on local storage and cached in memory before training. BVLC Caffe, revision 2a1c552b66f026c7508d390b526f2495ed3be594
2 System configuration: CPU threads per core: two cores per socket: 28 sockets, two NUMA nodes, two CPU family: 6 model, 85 model name: Intel Xeon Platinum 8180 processor at 2.50 GHz, HyperThreading: ON turbo: ON, memory 376 GB (12x32 GB), 24 slots, 12 occupied, 2666 MHz disks Intel RS3WC080 x 3 (800 GB, 1.6 TB, 6 TB) BIOS: SE5C620.86B.00.01.0004. 070920180847 (microcode version 0x200004d), Centos Linux 7.4.1708 (core) kernel 3.10.0-693.11.6.el7.x86_64, TensorFlow Source, commit: 6a0b536a779f485edc25f6a11335b5e640acc8ab, Intel MKL DNN version: 4e333787e0d66a1dca1218e99a891d493dbc8ef1, TensorFlow benchmarks
______
You May Also Like
Optimize End-to-End Data Science and Machine Learning Acceleration
Watch
Ignite the Next Generation of Deep Learning
Listen
Intel® oneAPI Math Kernel Library
Accelerate math processing routines, including matrix algebra, fast Fourier transforms (FFT), and vector math. Part of the Intel® oneAPI Base Toolkit.
Get It Now
See All Tools