Hello, everyone! In the first part of this blog post series, we introduced the BioDynaMo project, which is part of CERN openlab. Specifically, we gave an overview of the project's history, current status and the goal for this summer. The latter being implementing a distributed runtime prototype which can run both on high-performance clusters and cloud environments.
Today, we will first discuss the nature of the simulations we are interested in, and then the design of the distributed architecture along with the tools we used.
Simulation model
As we described in the previous post, we simulate biological processes which [take place in biological tissues]. We model these tissues as a system of many interacting cells, which are mostly affected by their microenvironment. More precisely, each cell influences and reacts to its neighboring cell within a specified radius. Additionally, there can be various kinds of interactions between the same pair of cells, e.g., physical, biochemical and more. For each simulation step, we compute these interactions for all the cell pairs.
Below, you can see a sample video of cell division simulated on BioDynaMo and visualized by the ParaView software:

Communication between nodes
When the simulation workload cannot be handled by a single machine, the cells are partitioned into multiple nodes, based on their position, by creating vertical slices in the 3D-space. If this step is done correctly, each node will have approximately the same number of cells. This way, each node simulates a subset of all the cells. Effectively, all the nodes together simulate the entire tissue. So, are we done? Not so fast!
- What about the interactions between cell pairs that are separated by different nodes?
Well, there is bad news, and there is good news. The bad news is that we need a special mechanism to exchange cells between the nodes involved, to be able to calculate these interactions. The good news is that fortunately, the cell interactions can only be present between neighboring slices, and thus "adjacent" nodes. This restriction significantly reduces the coupling among the nodes, as every node will exchange data with at most two other nodes. Moreover, this results in minimal communication overhead for the network, compared to the costly N-to-N communication.
Below, we show a possible cell partition between two nodes. The cells are indicated by black dots:
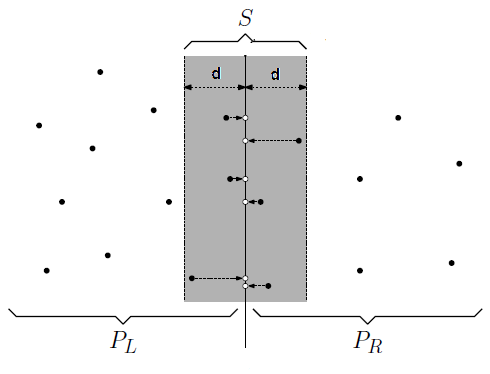
The regions, marked with gray, are called halo regions. They define the maximum allowed distance for cell-to-cell interaction. At each simulation step, adjacent nodes must exchange the cells inside their halo regions, so each node's partial simulation can proceed to the next step.
Architecture and tools decision
Having examined the simulation process in detail, we thought it was best to go with the Leader/Worker communication model. One obvious reason is that, by using this approach, the existing HPC systems and the Cloud infrastructures can be programmed effortlessly. Furthermore, it is possible to scale our computations to many more nodes, compared to the P2P model.
- Which tools are suitable for our case?
First, let's try to summarize in some of the requirements for our distributed runtime:
- Low network latency, as the "adjacent" nodes regularly exchange data
- High throughput, as the "halo regions" can become quite large, e.g., hundreds of MBs
- Support for broker & peer-to-peer communication, for the leader-worker and worker-worker communication
- Fault-tolerant to network and system failures with recovery support, as the cloud environments are error-prone
- Written in C or C++, to integrate quickly with our current implementation
In HPC clusters, MPI is pretty dominant. Taking advantage of the tightly-coupled nodes, MPI provides total control over the transmitted low-level data, mechanisms for managing and launching new jobs and fast communication. However, the lack of fault-tolerance is a major issue, and we cannot ignore it. In contrast, in cloud environments a variety of frameworks are used; Apache Spark, Hadoop, MapReduce and just a few examples closer to our application. Most of them have some fault-tolerance and can be very robust and fast. Unfortunately, they require expressing the computations to Map/Reduce style, which is not applicable to our case because of the custom communication between the workers.
- Is there a middle-road approach?
ZeroMQ

"It's sockets on steroids. It's like mailboxes with routing. It's fast!"
ZeroMQ (or ØMQ) is a high-level message passing library which provides high-speed asynchronous I/O, atomic delivery of messages in FIFO order and flexible messaging patterns. Also, it is one of the few network "message-queuing libraries" that doesn't require intermediate message handling (i.e. broker-less communication), contrary to the famous RabbitMQ and ActiveMQ frameworks.
The asynchronous I/O enables us to overlap computation with communication, effectively reducing the communication overhead. Moreover, ZeroMQ provides fault-tolerance on low-level networking errors, which helps us focus on the implementation of our architecture and protocol, rather than dealing with raw TCP sockets. However, it does not provide an end-to-end message delivery guarantee.
More technical details are coming up in the next post. We will begin from an existing reliability pattern called Majordomo (described here), and along with the ZMQPP high-level C++ wrapper, our runtime starts taking shape!
"